 +
+
+
+
+
+
+
+ +
+ +
+
+ Agent-Oriented Programming for Building LLM Applications. +
+ + ++ LangChain provides the engineering platform and open source frameworks developers use to build, test, and deploy reliable AI agents. +
+ + ++ The OpenAI Agents SDK allows you to build agentic AI applications in a lightweight and easy-to-use package with minimal abstractions. By the way, both vLLM and SGLang offer compatible services. +
+ + ++ Why use the Agent SDKs and all these abstractions? If you want to take control of the foundation of LLM Agents, + in this AI era, you can always start from scratch and build your own "high-scrapers". +
+ + ++ We are still testing all other agentic frameworks. + Meanwhile, "Raw HTTP" methods can provide `base_url` and `api_key` as AgentJet endpoint, + which theoretically can support most agentic frameworks. +
+ + +
+  +
+  +
+ **Basic Metadata** — Project name, experiment name, experiment directory, and backbone selection
+ - `project_name`, `experiment_name`, `experiment_dir`
+ - `backbone`: Select training backend (`debug`, `trinity`, or `verl`)
+
+-
**Basic Metadata** — Project name, experiment name, experiment directory, and backbone selection
+ - `project_name`, `experiment_name`, `experiment_dir`
+ - `backbone`: Select training backend (`debug`, `trinity`, or `verl`)
+
+-  **Data & Reward** — How to load data and evaluate agents
+ - `task_reader`: Load training/validation samples
+ - `task_judge`: Evaluate agents and compute rewards
+ - `data`: Prompt/response length and batch sizes
+
+-
**Data & Reward** — How to load data and evaluate agents
+ - `task_reader`: Load training/validation samples
+ - `task_judge`: Evaluate agents and compute rewards
+ - `data`: Prompt/response length and batch sizes
+
+-  **Model & Rollout** — Model configuration and agent interaction
+ - `model`: Base model to train
+ - `rollout`: Agent-environment interaction settings
+ - `context_tracker`: Conversation/history management
+
+
**Model & Rollout** — Model configuration and agent interaction
+ - `model`: Base model to train
+ - `rollout`: Agent-environment interaction settings
+ - `context_tracker`: Conversation/history management
+
+See all configurations applied in a real training example.
+Monitor and visualize your training progress.
+You have prepared task data in JSONL format locally.
Load tasks from HuggingFace Hub (e.g., GSM8K, MATH).
Tasks come from a running environment service.
Set up reward functions to evaluate agent outputs.
+Complete reference for all configuration options.
+ in the yaml file:
+
+1. **Read tasks** (corresponding config field: `ajet.task_reader`)
+2. **Define the workflow** (corresponding config field: `ajet.rollout.user_workflow`)
+ - Example: if the AgentScope workflow is defined in the `ExampleAgentScopeWorkflow` class in `tutorial/example_appworld/appworld.py`
+ - Then set `ajet.rollout.user_workflow = "tutorial.example_appworld.appworld->ExampleAgentScopeWorkflow"`
+3. **Define the scoring function** (corresponding config field: `ajet.task_judge.judge_protocol`)
+ - Example: `ajet.task_judge.judge_protocol = "ajet.task_judge.env_service_as_judge->EnvServiceJudge"`
+4. **Specify the model** (corresponding config field: `ajet.model.path`)
+
+```yaml
+ajet:
+ project_name: example_appworld
+ experiment_name: "read_yaml_name"
+ task_judge:
+ # [key] Implement and select the evaluation function
+ judge_protocol: ajet.task_judge.env_service_as_judge->EnvServiceJudge
+ model:
+ # [key] Set the model to be trained
+ path: YOUR_MODEL_PATH
+ rollout:
+ # [key] Implement and select the Agent
+ user_workflow: tutorial.example_appworld.appworld->ExampleAgentScopeWorkflow
+ force_disable_toolcalls: True
+ debug:
+ debug_max_parallel: 1
+ debug_first_n_tasks: 1
+```
+
+## 4. Results
+
+### 4.1 Training Curve
+
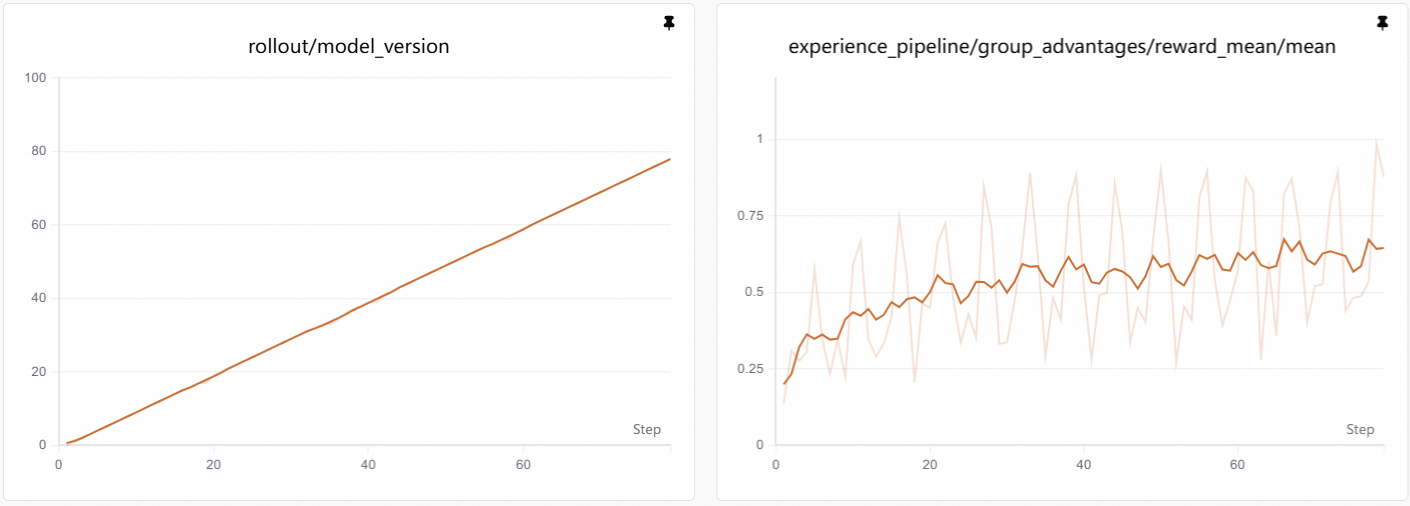
+
+
+> **Visualization:** Training curves are generated by SwanLab. See [Visualization Tools](./visualization.md) for setup and usage.
+
+As training progresses, reward increases. This usually means the agent becomes more stable on **two things**:
+
+* **Following correct API protocols**: it learns to look up API documentation before calling, and uses valid API endpoints instead of hallucinating non-existent ones.
+* **Completing multi-step workflows**: it can properly obtain access tokens and chain multiple API calls to accomplish complex tasks.
+
+
+### 4.2 Case Study
+
+#### Before tuning:
+
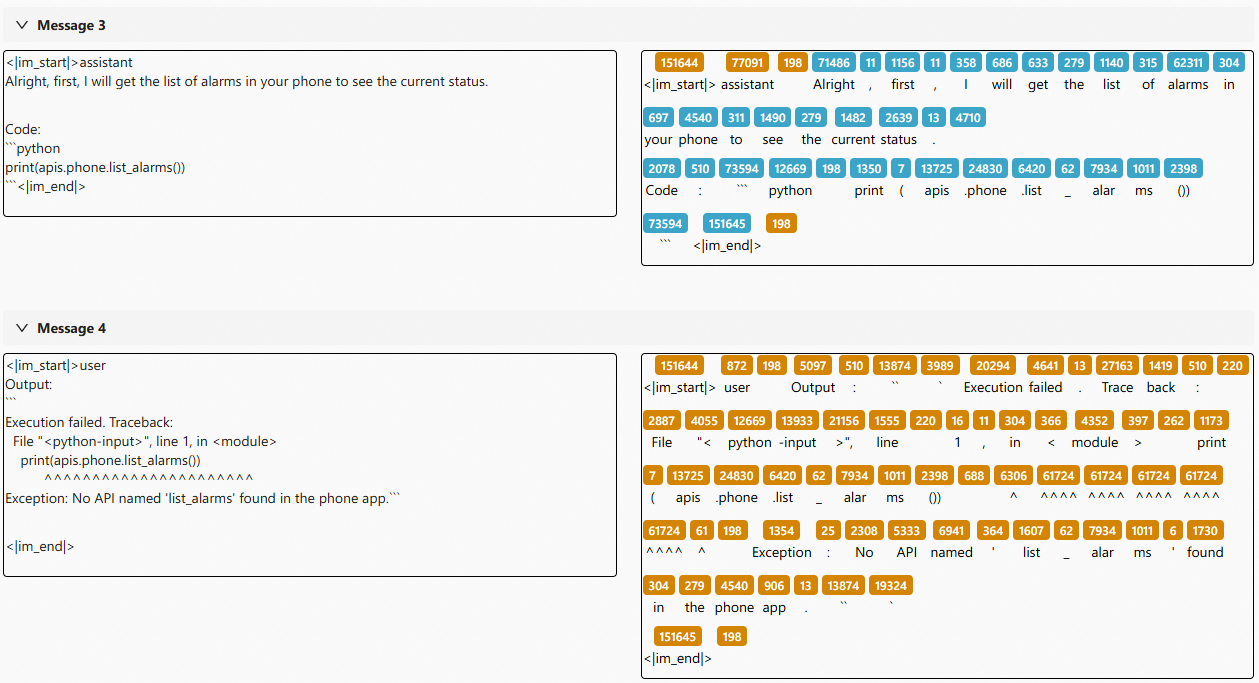
+1. Frequently call non-existent APIs
+
+
+
+The agent hallucinates API names without checking whether they exist, leading to repeated failures.
+
+2. Fail to follow the instructions to obtain an access token
+
+
+
+The agent attempts to call protected APIs without first obtaining the required access token, resulting in authentication errors.
+
+#### After tuning:
+
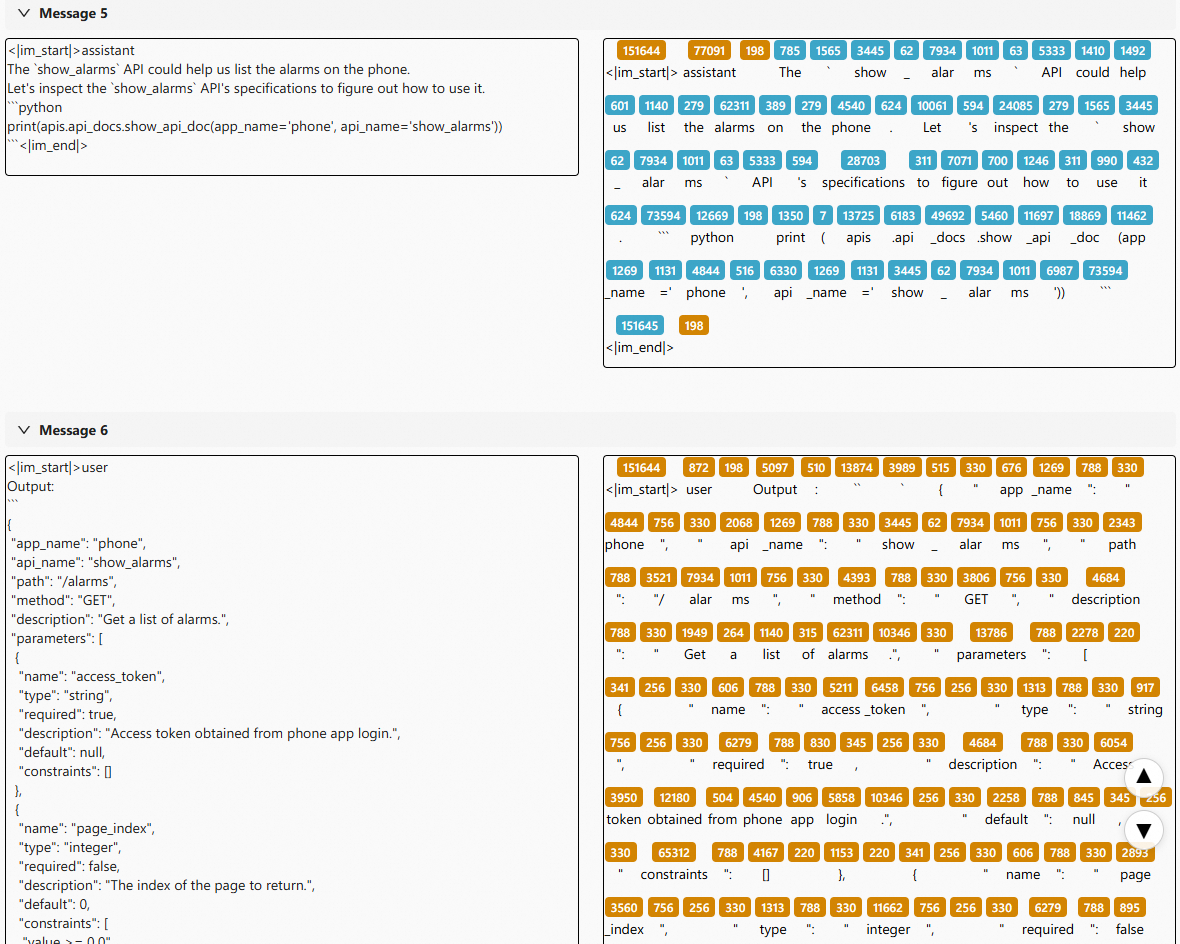
+1. Look up the API documentation first, and learn to use valid APIs
+
+
+
+The agent now checks available APIs before making calls, avoiding hallucinated endpoints.
+
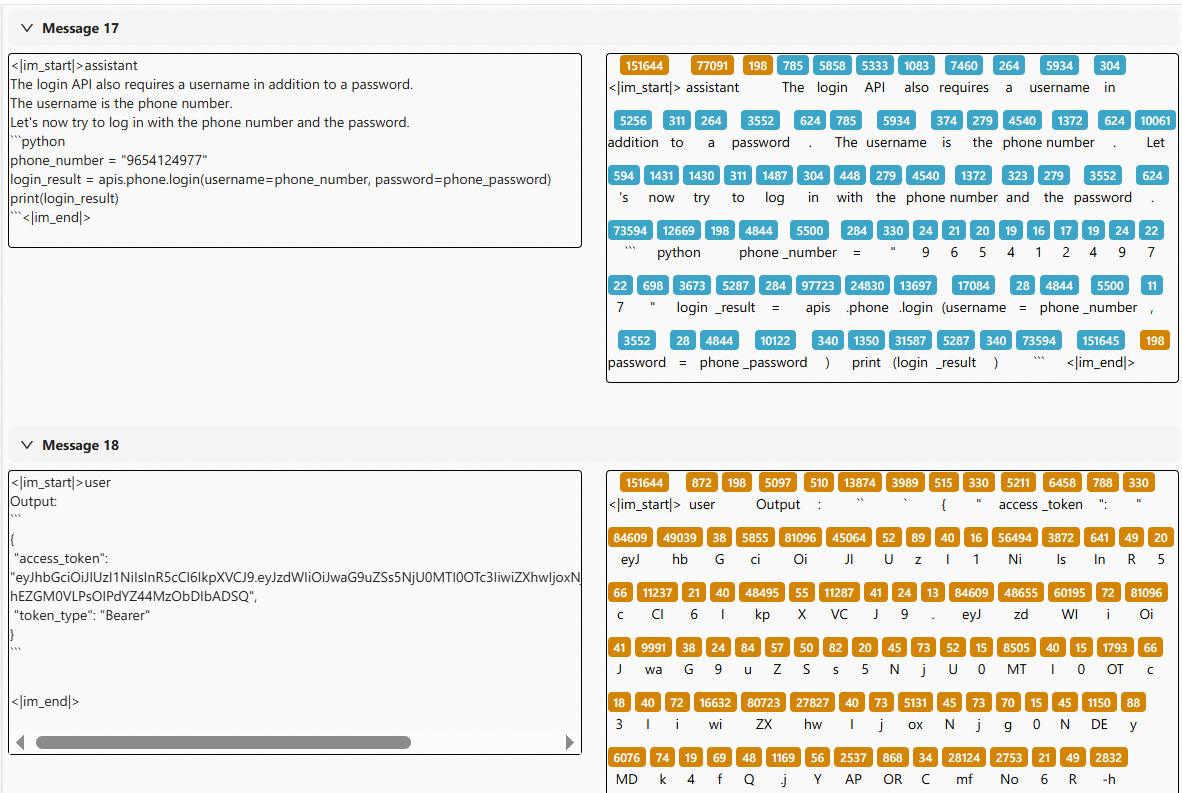
+2. Learn to obtain an access token correctly
+
+
+
+The agent properly handles the authentication step before accessing protected APIs.
+
+> **Token-level Visualization:** These detailed logs are generated by Beast-Logger. See [Beast-Logger Usage](./beast_logger.md) for more details.
diff --git a/docs/en/example_countdown.md b/docs/en/example_countdown.md
new file mode 100644
index 00000000..ff8ec4e3
--- /dev/null
+++ b/docs/en/example_countdown.md
@@ -0,0 +1,203 @@
+# Countdown
+
+## 1. Overview
+
+Countdown is a math puzzle game. Given a list of numbers and a target number, the player needs to use the numbers and the four basic arithmetic operations (addition, subtraction, multiplication, and division) to form an expression that evaluates to the target number. Each number can be used only once, but parentheses can be used freely to change the order of operations.
+
+## 2. Quick Start
+
+### 2.1 Preparation
+Download the `Jiayi-Pan/Countdown-Tasks-3to4` dataset and split it into training and test sets:
+
+```bash
+python tutorial/example_countdown/prepare_data.py --target=Jiayi-Pan/Countdown-Tasks-3to4 --path=/the/path/to/store/dataset
+```
+
+The Countdown dataset contains the `target` and `nums` fields and requires custom data formatting logic. For example, when using the `huggingface_dat_repo` task reader method, you need to modify the `_load_dataset_split` method in `ajet/task_reader/hf_dataset_reader.py`:
+
+```python
+task = Task(
+ main_query=json.dumps({'target': example["target"], 'nums': example["nums"]}),
+ init_messages=[],
+ task_id=str(idx),
+ env_type="no_env",
+ metadata=example,
+)
+```
+
+### 2.2 Start Training
+
+Simply run the following command:
+
+```bash
+# It is recommended to kill all ray, vllm, and env_service processes before starting ( python launcher.py --kill="python|ray|vllm" )
+ajet --conf tutorial/example_countdown/countdown.yaml --backbone='verl'
+```
+
+ symbols.
+
+1. Read task (corresponds to configuration field `ajet.task_reader`)
+2. Define Workflow (corresponds to configuration field `ajet.rollout.user_workflow`)
+ - Example: If agentscope workflow is defined in `ExampleCountdownLearn` class of `tutorial/example_countdown/countdown.py`
+ - Then set `ajet.rollout.user_workflow`=`tutorial.example_countdown.countdown->ExampleCountdownLearn`
+3. Define scoring function (corresponds to configuration field `ajet.task_judge.judge_protocol`)
+ - Example: If agentscope workflow is defined in `CountdownAnswerAsJudge` class of `tutorial/example_countdown/countdown_answer_as_judge.py`
+ - Then set `ajet.task_judge.judge_protocol`=`tutorial.example_countdown.countdown_answer_as_judge->CountdownAnswerAsJudge`
+4. Specify model (corresponds to configuration field `ajet.model.path`)
+
+```yaml
+ajet:
+ task_reader:
+ type: huggingface_dat_repo # [key] `env_service` or `dataset_file` or `huggingface_dat_repo` or `data_generation`
+ rollout:
+ user_workflow: tutorial.example_countdown.countdown->ExampleCountdownLearn # [key] Write and select Agent
+ task_judge:
+ # [key] Write and select evaluation function
+ judge_protocol: tutorial.example_countdown.countdown_answer_as_judge->CountdownAnswerAsJudge
+ model:
+ # [key] Set the model to be trained
+ path: YOUR_MODEL_PATH
+```
+
+### 3.3 Code Map
+
+- `tutorial/example_countdown/countdown.py`: defines the AgentScope workflow (e.g., `ExampleCountdownLearn`).
+- `tutorial/example_countdown/countdown.yaml`: wires together task reader, workflow, judge, and model.
+
+### 3.4 Reward/Evaluation Mechanism
+A simple Judge is provided in `tutorial/example_countdown/countdown_answer_as_judge.py`. You can create new Judge code anywhere in the project.
+
+Judge input parameters include:
+
+```
+workflow_task: Task information(if reference answer is included, it can be retrieved from here)
+workflow_output: Task information output (final_answer needs to be added manually)
+```
+
+Judge return values:
+
+- raw_reward
+- is_success
+
+## 4. Results
+
+### 4.1 Training Curves/Metrics
+
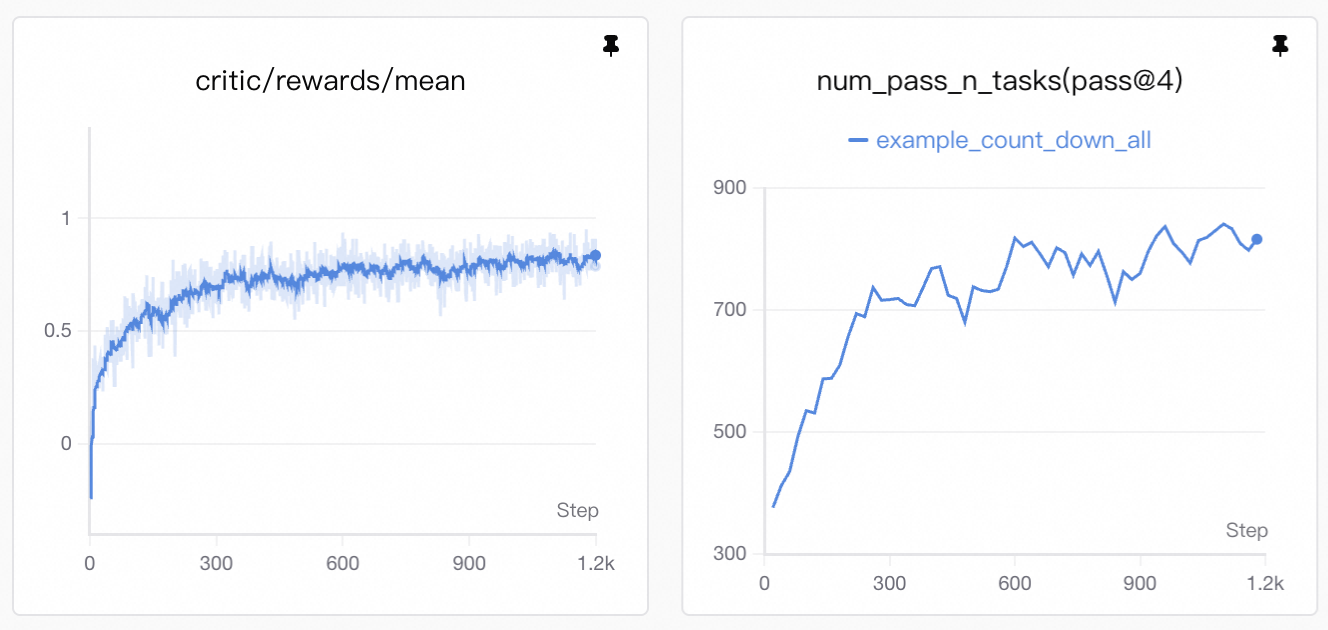
+
+
+> **Visualization:** Training curves are generated by SwanLab. See [Visualization Tools](./visualization.md) for setup and usage.
+
+The upward trend in reward reflects improvement in two key areas:
+
+* **Format compliance**: the agent learns to emit well-formed `
in the yaml file:
+
+1. **Read tasks** (corresponding config field: `ajet.task_reader`)
+2. **Define the workflow** (corresponding config field: `ajet.rollout.user_workflow`)
+ - Example: if the AgentScope workflow is defined in the `ExampleAgentScopeWorkflow` class in `tutorial/example_appworld/appworld.py`
+ - Then set `ajet.rollout.user_workflow = "tutorial.example_appworld.appworld->ExampleAgentScopeWorkflow"`
+3. **Define the scoring function** (corresponding config field: `ajet.task_judge.judge_protocol`)
+ - Example: `ajet.task_judge.judge_protocol = "ajet.task_judge.env_service_as_judge->EnvServiceJudge"`
+4. **Specify the model** (corresponding config field: `ajet.model.path`)
+
+```yaml
+ajet:
+ project_name: example_appworld
+ experiment_name: "read_yaml_name"
+ task_judge:
+ # [key] Implement and select the evaluation function
+ judge_protocol: ajet.task_judge.env_service_as_judge->EnvServiceJudge
+ model:
+ # [key] Set the model to be trained
+ path: YOUR_MODEL_PATH
+ rollout:
+ # [key] Implement and select the Agent
+ user_workflow: tutorial.example_appworld.appworld->ExampleAgentScopeWorkflow
+ force_disable_toolcalls: True
+ debug:
+ debug_max_parallel: 1
+ debug_first_n_tasks: 1
+```
+
+## 4. Results
+
+### 4.1 Training Curve
+
+
+
+> **Visualization:** Training curves are generated by SwanLab. See [Visualization Tools](./visualization.md) for setup and usage.
+
+As training progresses, reward increases. This usually means the agent becomes more stable on **two things**:
+
+* **Following correct API protocols**: it learns to look up API documentation before calling, and uses valid API endpoints instead of hallucinating non-existent ones.
+* **Completing multi-step workflows**: it can properly obtain access tokens and chain multiple API calls to accomplish complex tasks.
+
+
+### 4.2 Case Study
+
+#### Before tuning:
+
+1. Frequently call non-existent APIs
+
+
+
+The agent hallucinates API names without checking whether they exist, leading to repeated failures.
+
+2. Fail to follow the instructions to obtain an access token
+
+
+
+The agent attempts to call protected APIs without first obtaining the required access token, resulting in authentication errors.
+
+#### After tuning:
+
+1. Look up the API documentation first, and learn to use valid APIs
+
+
+
+The agent now checks available APIs before making calls, avoiding hallucinated endpoints.
+
+2. Learn to obtain an access token correctly
+
+
+
+The agent properly handles the authentication step before accessing protected APIs.
+
+> **Token-level Visualization:** These detailed logs are generated by Beast-Logger. See [Beast-Logger Usage](./beast_logger.md) for more details.
diff --git a/docs/en/example_countdown.md b/docs/en/example_countdown.md
new file mode 100644
index 00000000..ff8ec4e3
--- /dev/null
+++ b/docs/en/example_countdown.md
@@ -0,0 +1,203 @@
+# Countdown
+
+## 1. Overview
+
+Countdown is a math puzzle game. Given a list of numbers and a target number, the player needs to use the numbers and the four basic arithmetic operations (addition, subtraction, multiplication, and division) to form an expression that evaluates to the target number. Each number can be used only once, but parentheses can be used freely to change the order of operations.
+
+## 2. Quick Start
+
+### 2.1 Preparation
+Download the `Jiayi-Pan/Countdown-Tasks-3to4` dataset and split it into training and test sets:
+
+```bash
+python tutorial/example_countdown/prepare_data.py --target=Jiayi-Pan/Countdown-Tasks-3to4 --path=/the/path/to/store/dataset
+```
+
+The Countdown dataset contains the `target` and `nums` fields and requires custom data formatting logic. For example, when using the `huggingface_dat_repo` task reader method, you need to modify the `_load_dataset_split` method in `ajet/task_reader/hf_dataset_reader.py`:
+
+```python
+task = Task(
+ main_query=json.dumps({'target': example["target"], 'nums': example["nums"]}),
+ init_messages=[],
+ task_id=str(idx),
+ env_type="no_env",
+ metadata=example,
+)
+```
+
+### 2.2 Start Training
+
+Simply run the following command:
+
+```bash
+# It is recommended to kill all ray, vllm, and env_service processes before starting ( python launcher.py --kill="python|ray|vllm" )
+ajet --conf tutorial/example_countdown/countdown.yaml --backbone='verl'
+```
+
+ symbols.
+
+1. Read task (corresponds to configuration field `ajet.task_reader`)
+2. Define Workflow (corresponds to configuration field `ajet.rollout.user_workflow`)
+ - Example: If agentscope workflow is defined in `ExampleCountdownLearn` class of `tutorial/example_countdown/countdown.py`
+ - Then set `ajet.rollout.user_workflow`=`tutorial.example_countdown.countdown->ExampleCountdownLearn`
+3. Define scoring function (corresponds to configuration field `ajet.task_judge.judge_protocol`)
+ - Example: If agentscope workflow is defined in `CountdownAnswerAsJudge` class of `tutorial/example_countdown/countdown_answer_as_judge.py`
+ - Then set `ajet.task_judge.judge_protocol`=`tutorial.example_countdown.countdown_answer_as_judge->CountdownAnswerAsJudge`
+4. Specify model (corresponds to configuration field `ajet.model.path`)
+
+```yaml
+ajet:
+ task_reader:
+ type: huggingface_dat_repo # [key] `env_service` or `dataset_file` or `huggingface_dat_repo` or `data_generation`
+ rollout:
+ user_workflow: tutorial.example_countdown.countdown->ExampleCountdownLearn # [key] Write and select Agent
+ task_judge:
+ # [key] Write and select evaluation function
+ judge_protocol: tutorial.example_countdown.countdown_answer_as_judge->CountdownAnswerAsJudge
+ model:
+ # [key] Set the model to be trained
+ path: YOUR_MODEL_PATH
+```
+
+### 3.3 Code Map
+
+- `tutorial/example_countdown/countdown.py`: defines the AgentScope workflow (e.g., `ExampleCountdownLearn`).
+- `tutorial/example_countdown/countdown.yaml`: wires together task reader, workflow, judge, and model.
+
+### 3.4 Reward/Evaluation Mechanism
+A simple Judge is provided in `tutorial/example_countdown/countdown_answer_as_judge.py`. You can create new Judge code anywhere in the project.
+
+Judge input parameters include:
+
+```
+workflow_task: Task information(if reference answer is included, it can be retrieved from here)
+workflow_output: Task information output (final_answer needs to be added manually)
+```
+
+Judge return values:
+
+- raw_reward
+- is_success
+
+## 4. Results
+
+### 4.1 Training Curves/Metrics
+
+
+
+> **Visualization:** Training curves are generated by SwanLab. See [Visualization Tools](./visualization.md) for setup and usage.
+
+The upward trend in reward reflects improvement in two key areas:
+
+* **Format compliance**: the agent learns to emit well-formed `Explore multi-agent collaborative training.
+Train agents for real-world app interactions.
+Monitor and analyze your training progress.
+Run your first training command and explore examples.
+Step-by-step guide to build and train your own agent.
+Training a math agent that can write Python code to solve mathematical problems.
+Creating an AppWorld agent using AgentScope and training it for real-world tasks.
+Developing Werewolves RPG agents and training them for strategic gameplay.
+Learning to ask questions like a doctor for medical consultation scenarios.
+Writing a countdown game using AgentScope and solving it with RL.
+Solving a frozen lake walking puzzle using AgentJet's reinforcement learning.
+
+Define your agent logic by inheriting the Workflow class, supporting both simple and multi-agent setups.
+Load training tasks from JSONL files, HuggingFace datasets, or auto-generate from documents.
+Evaluates agent outputs and assigns rewards to guide the training process.
+Set up AgentJet environment and dependencies.
+Run your first training in minutes.
+Training a math agent that can write Python code to solve mathematical problems.
+Creating an AppWorld agent using AgentScope and training it.
+Developing Werewolves RPG agents and training them.
+Learning to ask questions like a doctor.
+Writing and solving a countdown game with RL.
+Solving a frozen lake walking puzzle.
+Complete step-by-step guide to building your own agent from scratch.
+Detailed walkthrough of the Math Agent training example.
+Complete reference for all configuration options.
+See MathAnswerAsJudge in a complete training example.
+Learn to define trainable workflows and multi-agent setups.
+Configure data loading from various sources.
+Set up reward functions for your training.
+See the complete Math Agent implementation.
+Modern experiment tracking platform designed for AI research. Recommended.
Weights & Biases experiment tracking platform.
Simple text-based logging to standard output.
Token-level debugging and visualization.
+Auto-generate training data from documents.
+Official SwanLab documentation.
+ +
+ Know exactly which agents should be trained, or the number of agents is small
+ - Already finished basic debugging of your workflow
+ -
Know exactly which agents should be trained, or the number of agents is small
+ - Already finished basic debugging of your workflow
+ -  Do not need to change which agents are trained on the fly
+
+
+### 2. Convert Your Workflow to AgentJet Trainable Workflow
+
+The very first step is to create a class as a container to wrap your code:
+
+=== "`converted_workflow.py` - AgentJet Workflow"
+
+ ```python
+ from ajet import AjetTuner, Workflow, WorkflowOutput, WorkflowTask
+ class MyWorkflow(Workflow):
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+ # ... your ReActAgent workflow here ✈️ ...
+ return WorkflowOutput(reward=..., metadata={...})
+
+ ```
+
+
+Next, use the `tuner` argument, call its `tuner.as_agentscope_model()` method:
+
+=== "Before"
+
+ ```python
+ model = DashScopeChatModel(model_name="qwen-max", stream=False) # ✈️ change here
+ agent_instance = ReActAgent(
+ name=f"Friday",
+ sys_prompt="You are a helpful assistant",
+ model=model,
+ formatter=DashScopeChatFormatter(),
+ )
+ ```
+
+=== "After"
+
+ ```python
+ model = tuner.as_agentscope_model() # ✈️ change here
+ agent_instance = ReActAgent(
+ name=f"Friday",
+ sys_prompt="You are a helpful assistant",
+ model=model,
+ formatter=DashScopeChatFormatter(),
+ )
+ ```
+
+!!! warning "AjetTuner"
+ `AjetTuner` also has `.as_raw_openai_sdk_client()` and `.as_oai_baseurl_apikey()` method. But `.as_agentscope_model()` is more convenient for AgentScope agent workflow.
+
+
+
+### 3. Code Example
+
+
Do not need to change which agents are trained on the fly
+
+
+### 2. Convert Your Workflow to AgentJet Trainable Workflow
+
+The very first step is to create a class as a container to wrap your code:
+
+=== "`converted_workflow.py` - AgentJet Workflow"
+
+ ```python
+ from ajet import AjetTuner, Workflow, WorkflowOutput, WorkflowTask
+ class MyWorkflow(Workflow):
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+ # ... your ReActAgent workflow here ✈️ ...
+ return WorkflowOutput(reward=..., metadata={...})
+
+ ```
+
+
+Next, use the `tuner` argument, call its `tuner.as_agentscope_model()` method:
+
+=== "Before"
+
+ ```python
+ model = DashScopeChatModel(model_name="qwen-max", stream=False) # ✈️ change here
+ agent_instance = ReActAgent(
+ name=f"Friday",
+ sys_prompt="You are a helpful assistant",
+ model=model,
+ formatter=DashScopeChatFormatter(),
+ )
+ ```
+
+=== "After"
+
+ ```python
+ model = tuner.as_agentscope_model() # ✈️ change here
+ agent_instance = ReActAgent(
+ name=f"Friday",
+ sys_prompt="You are a helpful assistant",
+ model=model,
+ formatter=DashScopeChatFormatter(),
+ )
+ ```
+
+!!! warning "AjetTuner"
+ `AjetTuner` also has `.as_raw_openai_sdk_client()` and `.as_oai_baseurl_apikey()` method. But `.as_agentscope_model()` is more convenient for AgentScope agent workflow.
+
+
+
+### 3. Code Example
+
+Training a math agent that can write Python code to solve mathematical problems.
+Learning to ask questions like a doctor for medical consultation scenarios.
+Writing a countdown game using AgentScope and solving it with RL.
+Solving a frozen lake walking puzzle using AgentJet's reinforcement learning.
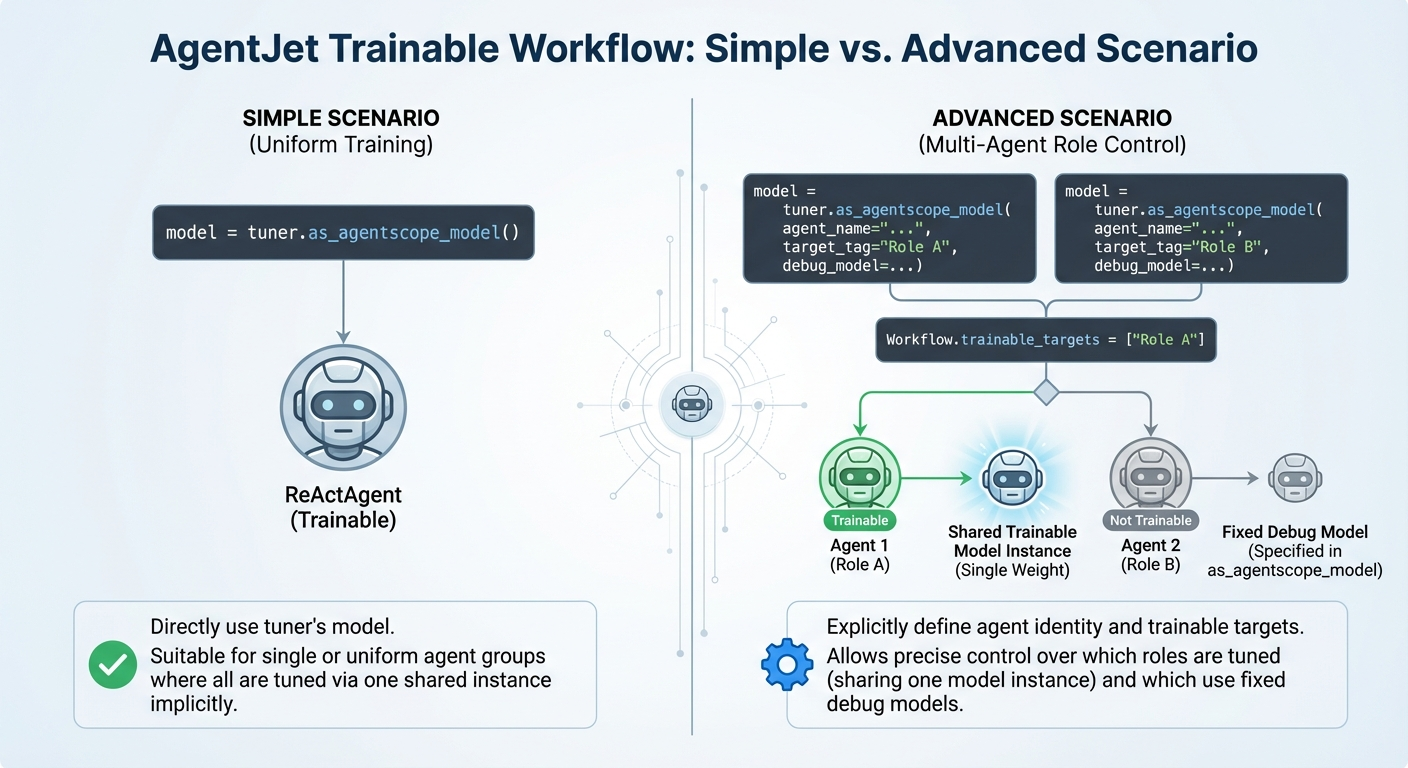
+ **Precisely control** which agents are fine-tuned
+ - Explicitly define the default model for agents **not being trained**
+ -  Switch trainable targets on the fly **without modifying** source code
+
+### 1. How to promote to advanced agent scenario:
+
+Simple, there are only two more issues that should be take care of in addition:
+
+i. **`.as_agentscope_model` has three hidden (optional) parameters, complete them for each agent.**
+
+| parameter | explanation |
+|----------|------------|
+| `agent_name` | The name of this agent |
+| `target_tag` | A tag that mark the agent category |
+| `debug_model` | The model used when this agent is not being tuned |
+
+=== "`as_agentscope_model()` parameters"
+
+ ```python
+ model_for_an_agent = tuner.as_agentscope_model(
+ agent_name="AgentFriday", # the name of this agent
+ target_tag="Agent_Type_1", # `target_tag in self.trainable_targets` means we train this agent, otherwise we do not train this agent.
+ debug_model=OpenAIChatModel(
+ model_name="Qwen/Qwen3-235B-A22B-Instruct-2507",
+ stream=False,
+ api_key="api_key",
+ ), # the model used when this agent is not in `self.trainable_targets`
+ )
+ ```
+
+ii. **`Workflow` has a hidden (optional) attribute called `trainable_targets`, config it.**
+
+| `trainable_targets` value | explanation |
+|----------|------------|
+| `trainable_targets = None` | All agents using `as_agentscope_model` will be trained |
+| `trainable_targets = ["Agent_Type_1", "Agent_Type_2"]` | Agents with `target_tag=Agent_Type_1`, `target_tag=Agent_Type_2`, ... will be trained |
+| `trainable_targets = []` | Illegal, no agents are trained |
+
+
+| Scenario | Model Used |
+|----------|------------|
+| `target_tag` in `trainable_targets` | Trainable model |
+| `target_tag` NOT in `trainable_targets` | Registered `debug_model` |
+
+
+
+!!! warning
+ Regardless of `target_tag` differences, all agents share a single model instance (one model weight to play different roles, the model receives different perceptions when playing different roles).
+
+
+### 2. Multi-Agent Example
+
+Here's a complete example with multiple agent roles (Werewolves game):
+
+=== "`tutorial/example_werewolves/start.py`"
+ ```python
+ class ExampleWerewolves(Workflow):
+ trainable_targets: List[str] | None = Field(default=["werewolf"], description="List of agents to be fine-tuned.")
+
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+
+ # ensure trainable targets is legal
+ assert self.trainable_targets is not None, "trainable_targets cannot be None in ExampleWerewolves (because we want to demonstrate a explicit multi-agent case)."
+
+ # bad guys and good guys cannot be trained simultaneously
+ # (because mix-cooperation-competition MARL needs too many advanced techniques to be displayed here)
+ if "werewolf" in self.trainable_targets:
+ assert len(self.trainable_targets) == 1, "Cannot train hostile roles simultaneously."
+ else:
+ assert len(self.trainable_targets) != 0, "No trainable targets specified."
+
+ # make and shuffle roles (fix random seed for reproducibility)
+ roles = ["werewolf"] * 3 + ["villager"] * 3 + ["seer", "witch", "hunter"]
+ task_id = workflow_task.task.metadata["random_number"]
+ np.random.seed(int(task_id))
+ np.random.shuffle(roles)
+
+ # initialize agents
+ players = []
+ for i, role in enumerate(roles):
+ default_model = OpenAIChatModel(
+ model_name="Qwen/Qwen3-235B-A22B-Instruct-2507",
+ stream=False,
+ api_key="no_api_key",
+ )
+ model_for_this_agent = tuner.as_agentscope_model(
+ agent_name=f"Player{i + 1}", # the name of this agent
+ target_tag=role, # `target_tag in self.trainable_targets` means we train this agent, otherwise we do not train this agent.
+ debug_model=default_model, # the model used when this agent is not in `self.trainable_targets`
+ )
+ agent = ReActAgent(
+ name=f"Player{i + 1}",
+ sys_prompt=get_official_agent_prompt(f"Player{i + 1}"),
+ model=model_for_this_agent,
+ formatter=DashScopeMultiAgentFormatter()
+ if role in self.trainable_targets
+ else OpenAIMultiAgentFormatter(),
+ max_iters=3 if role in self.trainable_targets else 5,
+ )
+ # agent.set_console_output_enabled(False)
+ players += [agent]
+
+ # reward condition
+ try:
+ good_guy_win = await werewolves_game(players, roles)
+ raw_reward = 0
+ is_success = False
+ if (good_guy_win and self.trainable_targets[0] != "werewolf") or (
+ not good_guy_win and self.trainable_targets[0] == "werewolf"
+ ):
+ raw_reward = 1
+ is_success = True
+ logger.warning(f"Raw reward: {raw_reward}")
+ logger.warning(f"Is success: {is_success}")
+ except BadGuyException as e:
+ logger.bind(exception=True).exception(
+ f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent)."
+ )
+ raw_reward = -0.1
+ is_success = False
+ except Exception as e:
+ logger.bind(exception=True).exception(
+ f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent)."
+ )
+ raw_reward = -0.1
+ is_success = False
+
+ return WorkflowOutput(reward=raw_reward, is_success=is_success)
+ ```
+
+!!! tip "Configuration Flexibility"
+ In this example:
+
+ - `role` describes an agent's in-game identity (werewolf, villager, etc.)
+ - `chosen_model` defines the default model when the role is not being trained
+ - You can flexibly switch training targets by modifying `trainable_targets`
+
+
+## TinkerJet
+
+Wrapping and training your agent on a machine without GPU.
+
+Working in progress and coming soon.
+
+
+## Next Steps
+
+
Switch trainable targets on the fly **without modifying** source code
+
+### 1. How to promote to advanced agent scenario:
+
+Simple, there are only two more issues that should be take care of in addition:
+
+i. **`.as_agentscope_model` has three hidden (optional) parameters, complete them for each agent.**
+
+| parameter | explanation |
+|----------|------------|
+| `agent_name` | The name of this agent |
+| `target_tag` | A tag that mark the agent category |
+| `debug_model` | The model used when this agent is not being tuned |
+
+=== "`as_agentscope_model()` parameters"
+
+ ```python
+ model_for_an_agent = tuner.as_agentscope_model(
+ agent_name="AgentFriday", # the name of this agent
+ target_tag="Agent_Type_1", # `target_tag in self.trainable_targets` means we train this agent, otherwise we do not train this agent.
+ debug_model=OpenAIChatModel(
+ model_name="Qwen/Qwen3-235B-A22B-Instruct-2507",
+ stream=False,
+ api_key="api_key",
+ ), # the model used when this agent is not in `self.trainable_targets`
+ )
+ ```
+
+ii. **`Workflow` has a hidden (optional) attribute called `trainable_targets`, config it.**
+
+| `trainable_targets` value | explanation |
+|----------|------------|
+| `trainable_targets = None` | All agents using `as_agentscope_model` will be trained |
+| `trainable_targets = ["Agent_Type_1", "Agent_Type_2"]` | Agents with `target_tag=Agent_Type_1`, `target_tag=Agent_Type_2`, ... will be trained |
+| `trainable_targets = []` | Illegal, no agents are trained |
+
+
+| Scenario | Model Used |
+|----------|------------|
+| `target_tag` in `trainable_targets` | Trainable model |
+| `target_tag` NOT in `trainable_targets` | Registered `debug_model` |
+
+
+
+!!! warning
+ Regardless of `target_tag` differences, all agents share a single model instance (one model weight to play different roles, the model receives different perceptions when playing different roles).
+
+
+### 2. Multi-Agent Example
+
+Here's a complete example with multiple agent roles (Werewolves game):
+
+=== "`tutorial/example_werewolves/start.py`"
+ ```python
+ class ExampleWerewolves(Workflow):
+ trainable_targets: List[str] | None = Field(default=["werewolf"], description="List of agents to be fine-tuned.")
+
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+
+ # ensure trainable targets is legal
+ assert self.trainable_targets is not None, "trainable_targets cannot be None in ExampleWerewolves (because we want to demonstrate a explicit multi-agent case)."
+
+ # bad guys and good guys cannot be trained simultaneously
+ # (because mix-cooperation-competition MARL needs too many advanced techniques to be displayed here)
+ if "werewolf" in self.trainable_targets:
+ assert len(self.trainable_targets) == 1, "Cannot train hostile roles simultaneously."
+ else:
+ assert len(self.trainable_targets) != 0, "No trainable targets specified."
+
+ # make and shuffle roles (fix random seed for reproducibility)
+ roles = ["werewolf"] * 3 + ["villager"] * 3 + ["seer", "witch", "hunter"]
+ task_id = workflow_task.task.metadata["random_number"]
+ np.random.seed(int(task_id))
+ np.random.shuffle(roles)
+
+ # initialize agents
+ players = []
+ for i, role in enumerate(roles):
+ default_model = OpenAIChatModel(
+ model_name="Qwen/Qwen3-235B-A22B-Instruct-2507",
+ stream=False,
+ api_key="no_api_key",
+ )
+ model_for_this_agent = tuner.as_agentscope_model(
+ agent_name=f"Player{i + 1}", # the name of this agent
+ target_tag=role, # `target_tag in self.trainable_targets` means we train this agent, otherwise we do not train this agent.
+ debug_model=default_model, # the model used when this agent is not in `self.trainable_targets`
+ )
+ agent = ReActAgent(
+ name=f"Player{i + 1}",
+ sys_prompt=get_official_agent_prompt(f"Player{i + 1}"),
+ model=model_for_this_agent,
+ formatter=DashScopeMultiAgentFormatter()
+ if role in self.trainable_targets
+ else OpenAIMultiAgentFormatter(),
+ max_iters=3 if role in self.trainable_targets else 5,
+ )
+ # agent.set_console_output_enabled(False)
+ players += [agent]
+
+ # reward condition
+ try:
+ good_guy_win = await werewolves_game(players, roles)
+ raw_reward = 0
+ is_success = False
+ if (good_guy_win and self.trainable_targets[0] != "werewolf") or (
+ not good_guy_win and self.trainable_targets[0] == "werewolf"
+ ):
+ raw_reward = 1
+ is_success = True
+ logger.warning(f"Raw reward: {raw_reward}")
+ logger.warning(f"Is success: {is_success}")
+ except BadGuyException as e:
+ logger.bind(exception=True).exception(
+ f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent)."
+ )
+ raw_reward = -0.1
+ is_success = False
+ except Exception as e:
+ logger.bind(exception=True).exception(
+ f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent)."
+ )
+ raw_reward = -0.1
+ is_success = False
+
+ return WorkflowOutput(reward=raw_reward, is_success=is_success)
+ ```
+
+!!! tip "Configuration Flexibility"
+ In this example:
+
+ - `role` describes an agent's in-game identity (werewolf, villager, etc.)
+ - `chosen_model` defines the default model when the role is not being trained
+ - You can flexibly switch training targets by modifying `trainable_targets`
+
+
+## TinkerJet
+
+Wrapping and training your agent on a machine without GPU.
+
+Working in progress and coming soon.
+
+
+## Next Steps
+
+Configure data loading from files, HuggingFace, or environments.
+Set up reward functions to evaluate agent performance.
+ +
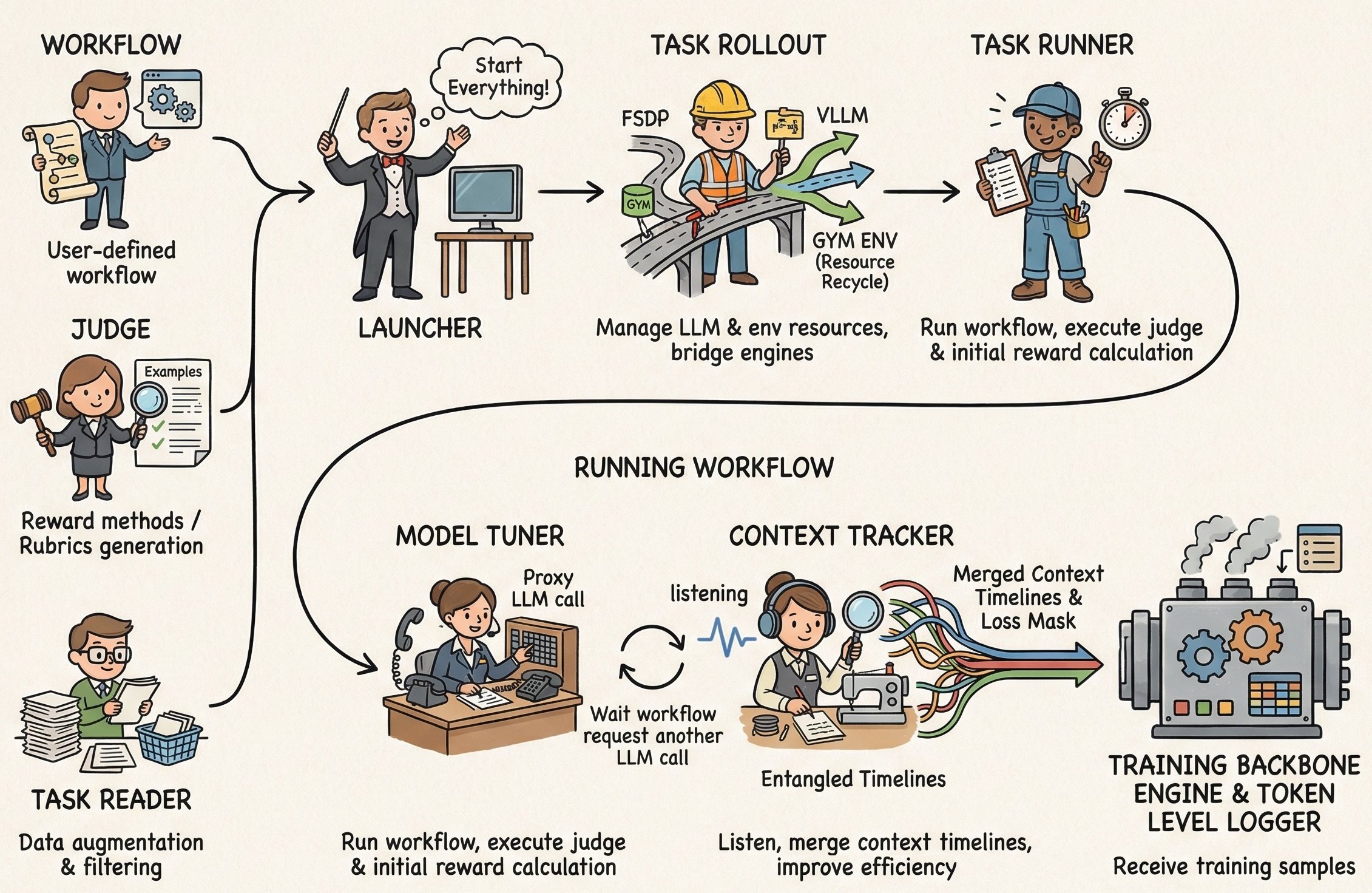
++ AgentJet simplifies the process of tuning the models that power your agent workflows. It supports nearly all major agent frameworks (e.g. agentscope, langchain), as well as framwork-less agents built from HTTP requests. +
+ + ++ Rich examples as beginner's tutorial: math agent, werewolves rpg, appworld ... All with step-by-step + guides. Covering various agentic frameworks.
+ + ++ Checkout AgentJet's community-powered, robot-assisted open-benchmarking system. + Share progress, compare training backbones, discover bugs and iterate faster than ever! + Click here to see AgentJet performance across tasks/versions/backbones. +
+ + ++ Built to support advanced multi-agent and multi-turn LLM workflows, + AgentJet intergrates timeline-merging algorithms that + automatically analyze and consolidate each agent's LLM timeline, + accelerating training speed 1.5x ~ 10x. +
+ + ++ Log token-level rollout details, capturing token IDs, token loss masks, and token log probabilities with web UI display. This Support workflow development, agent diagnostics, and facilitate research on advanced LLM algorithm studies. +
+ + ++ Support multiple training engines as backbone (VeRL and Trinity-RFT). Tinker backbone support will be released soon. + Choose from vLLM and SGLang as you wish. Say goodbye to training engine gaps. +
+ +Training a math agent that can write Python code to solve mathematical problems.
+Creating an AppWorld agent using AgentScope and training it for real-world tasks.
+Developing Werewolves RPG agents and training them for strategic gameplay.
+Learning to ask questions like a doctor for medical consultation scenarios.
+Writing a countdown game using AgentScope and solving it with RL.
+Solving a frozen lake walking puzzle using AgentJet's reinforcement learning.
+Define your agent logic by inheriting the Workflow class, supporting both simple and multi-agent setups.
+Load training tasks from JSONL files, HuggingFace datasets, or auto-generate from documents.
+Evaluates agent outputs and assigns rewards to guide the training process.
+
+Set up AgentJet environment and dependencies.
+Run your first training in minutes.
+Build and train your own agent from scratch.
+Explore detailed training examples.
+ +
+ +
-- 找到日志文件夹,默认在 `./launcher_record/exp_yaml_file_name/*` 下面
+- 找到日志文件夹,默认在 `./saved_experiments/exp_yaml_file_name/*` 下面
- 运行 `beast_logger_go` 启动日志浏览器,vscode端口映射8181端口
```bash
root@xxxx:/xxx/xxx/xxx# beast_logger_go
@@ -160,12 +159,18 @@ INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8181 (Press CTRL+C to quit)
```
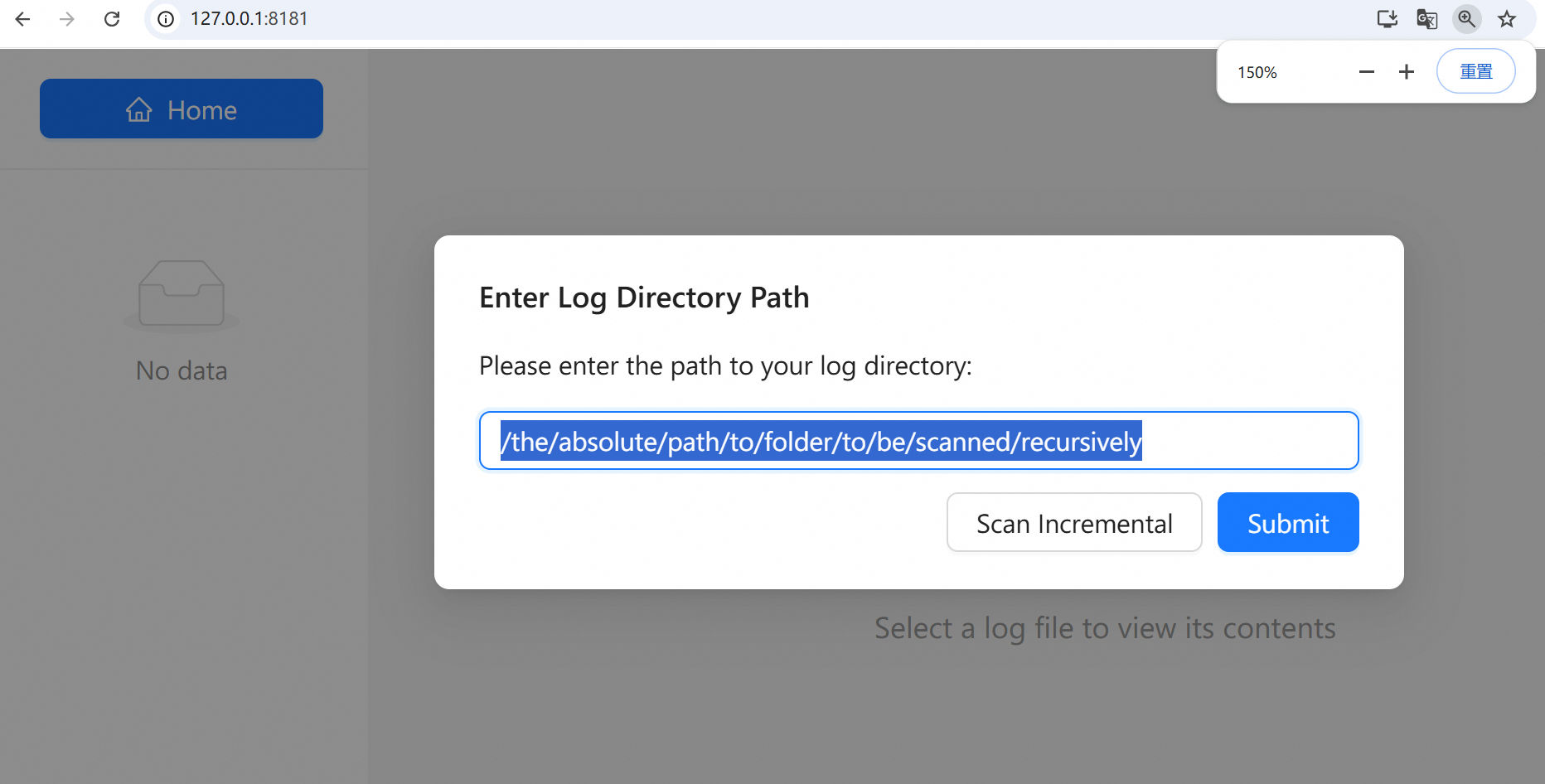
- 打开 http://127.0.0.1:8181,提示输入日志文件路径,填写日志文件夹的**绝对路径**,以下形式皆可
- - /mnt/data/qingxu.fu/astune/astune/launcher_record
- - /mnt/data/qingxu.fu/astune/astune/launcher_record/exp_yaml_file_name
- - /mnt/data/qingxu.fu/astune/astune/launcher_record/exp_yaml_file_name/2025_11_10_02_52/rollout
+ - /ajet/ajet/saved_experiments
+ - /ajet/ajet/saved_experiments/exp_yaml_file_name
+ - /ajet/ajet/saved_experiments/exp_yaml_file_name/2025_11_10_02_52/rollout
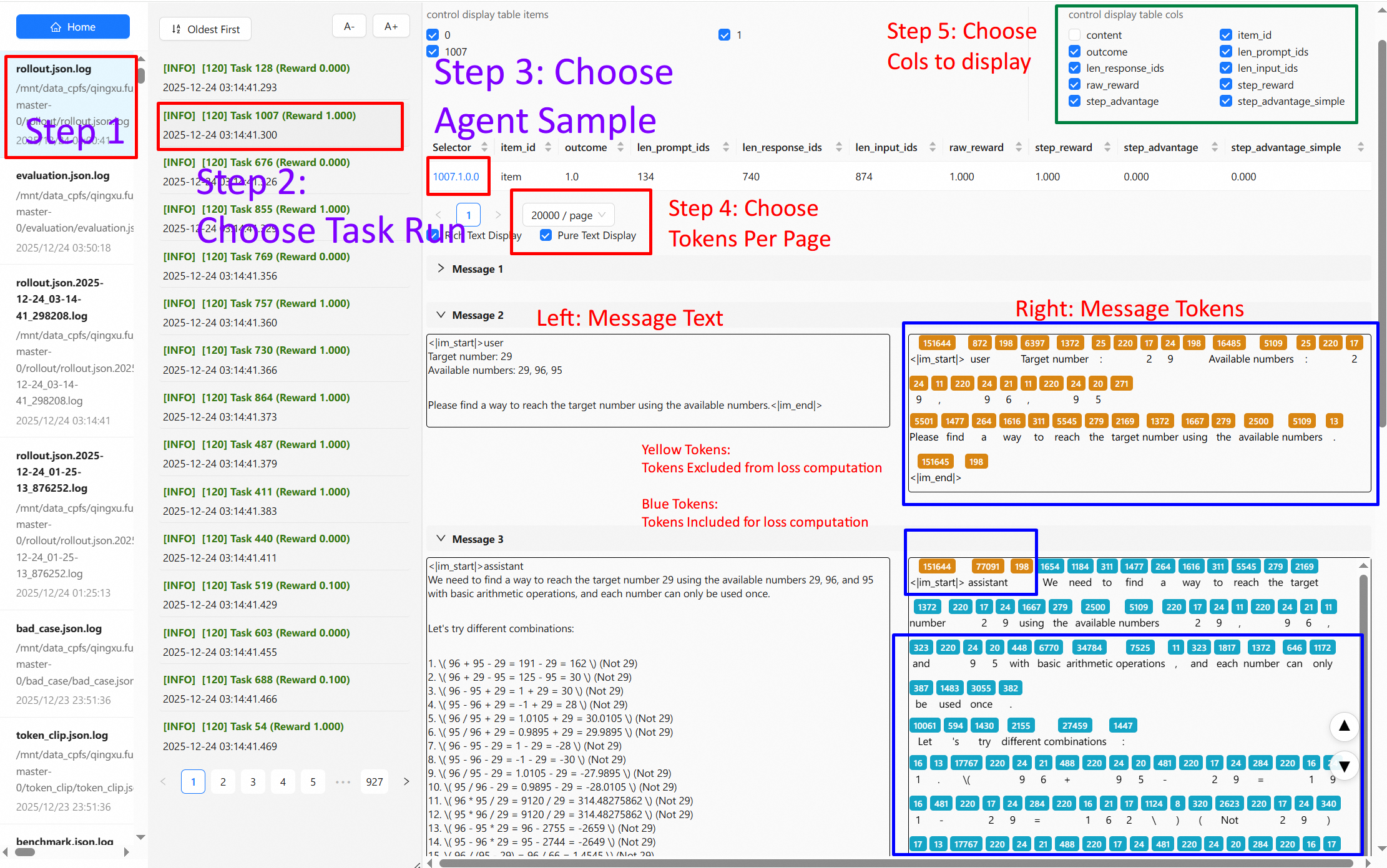
- 依次打开界面 **左侧** 的日志文件目标,**中间** 的日志条目,**右侧** 的交互记录,即可显示完整的轨迹
- 蓝色 Token 代表参与loss计算的 Token,黄色反之
-- 鼠标悬浮在 Token 上面可以查看 Token 的 **logprob** (暂时仅限trinity backbone)
\ No newline at end of file
+- 鼠标悬浮在 Token 上面可以查看 Token 的 **logprob** (暂时仅限trinity backbone)
+
+
+### 6. 参考训练曲线
+
+点击链接打开训练曲线:
+https://swanlab.cn/@binaryhusky/public/runs/96arcunrxlezdmcvmcdob/chart
diff --git a/tutorial/example_rubrics_judge/math_agent.py b/tutorial/example_rubrics_judge/math_agent.py
new file mode 100644
index 00000000..f035ac57
--- /dev/null
+++ b/tutorial/example_rubrics_judge/math_agent.py
@@ -0,0 +1,59 @@
+from agentscope.message import Msg
+from loguru import logger
+from pydantic import BaseModel, Field
+
+from ajet import AjetTuner, Workflow, WorkflowOutput, WorkflowTask
+
+
+def extract_final_answer(result) -> str:
+ """Extract the final answer from the agent's response."""
+ try:
+ if hasattr(result, "metadata") and isinstance(result.metadata, dict) and "result" in result.metadata:
+ return result.metadata["result"]
+ if hasattr(result, "content"):
+ if isinstance(result.content, dict) and "result" in result.content:
+ return result.content["result"]
+ return str(result.content)
+ return str(result)
+ except Exception as e:
+ logger.warning(f"Extract final answer error: {e}. Raw: {result}")
+ return str(result)
+
+
+class FinalResult(BaseModel):
+ result: str = Field(description="Your solution of the given math problem. Put your final answer in boxed format, e.g., \\boxed{42}")
+
+
+system_prompt = """
+You are an agent specialized in solving math problems with tools.
+Please solve the math problem given to you.
+You can write and execute Python code to perform calculation or verify your answer.
+You should return your final answer within \\boxed{{}}.
+"""
+
+
+class ExampleMathLearn(Workflow):
+ name: str = "math_agent_workflow"
+
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+ from agentscope.agent import ReActAgent
+ from agentscope.formatter import DashScopeChatFormatter
+ from agentscope.memory import InMemoryMemory
+ from agentscope.tool import Toolkit, execute_python_code
+
+ query = workflow_task.task.main_query
+ self.toolkit = Toolkit()
+ self.toolkit.register_tool_function(execute_python_code)
+ self.agent = ReActAgent(
+ name="math_react_agent",
+ sys_prompt=system_prompt,
+ model=tuner.as_agentscope_model(),
+ formatter=DashScopeChatFormatter(),
+ toolkit=self.toolkit,
+ memory=InMemoryMemory(),
+ )
+ self.agent.set_console_output_enabled(False)
+ msg = Msg("user", query, role="user")
+ result = await self.agent.reply(msg, structured_model=FinalResult)
+ final_answer = extract_final_answer(result)
+ return WorkflowOutput(reward=None, metadata={"final_answer": final_answer})
diff --git a/tutorial/example_rubrics_judge/r_judge.yaml b/tutorial/example_rubrics_judge/r_judge.yaml
new file mode 100644
index 00000000..f7a171ec
--- /dev/null
+++ b/tutorial/example_rubrics_judge/r_judge.yaml
@@ -0,0 +1,72 @@
+# ------------------ 主要配置 ------------------
+ajet:
+ project_name: example_rubrics_judge
+ task_reader:
+ type: huggingface_dat_repo # ✨✨✨✨ `env_service` or `dataset_file` or `huggingface_dat_repo`
+ # 如果选择 `huggingface_dat_repo` 以下配置生效
+ huggingface_dat_repo:
+ dataset_path: '/mnt/data_cpfs/qingxu.fu/dataset/openai/gsm8k/main'
+ training_split: "train"
+ validation_split: "test"
+
+ task_judge:
+ # ✨✨✨✨ 编写并选择评价函数
+ judge_type: rubrics_auto_grader # Options: 'customized_protocol', 'rubrics_auto_grader'
+ rubrics_auto_grader:
+ # rubrics begin
+ model_name: qwen-max
+ grader_mode: pointwise
+ language: en
+ min_score: 0
+ max_score: 1
+ success_threshold: 0.7
+ sampling_mode: all_samples
+ generate_number: 1
+ max_epochs: 2
+ max_retries: 3
+ aggregation_mode: keep_all
+ grader_name: Math Auto Grader
+ num_reference_samples: 20
+ query_field: main_query
+ answer_field: final_answer
+ reference_field: answer
+ input_data_type: dataset_file # `env_service` or `dataset_file` or `huggingface_dat_repo`
+ dataset_file:
+ training:
+ file_path: "tutorial/example_rm_auto_grader/rubrics_train.jsonl"
+
+
+ model:
+ # ✨✨✨✨ 设置待训练的模型
+ path: /mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2___5-14B-Instruct
+
+ rollout:
+ user_workflow: "tutorial.example_rubrics_judge.math_agent->ExampleMathLearn" # ✨✨✨✨ 编写并选择Agent
+ temperature: 0.7
+ max_env_worker: 80
+ num_repeat: 4
+ agent_madness_reward: 0.0
+
+ data:
+ train_batch_size: 64
+
+ debug:
+ debug_max_parallel: 1
+ debug_first_n_tasks: 1
+
+
+
+
+# ------------------ 不需要修改 ------------------
+hydra:
+ searchpath:
+ - file://ajet/default_config
+ - file://ajet/default_config/verl # verl only
+ - file://ajet/default_config/trinity # trinity only
+
+# ------------------ 不需要修改 ------------------
+defaults:
+ - verl_default # verl inherit 1/1
+ - trinity_default # trinity inherit 1/1
+ - ajet_default
+ - _self_
diff --git a/tutorial/example_werewolves/game.py b/tutorial/example_werewolves/game.py
new file mode 100644
index 00000000..7f72f9f9
--- /dev/null
+++ b/tutorial/example_werewolves/game.py
@@ -0,0 +1,349 @@
+# -*- coding: utf-8 -*-
+# pylint: disable=too-many-branches, too-many-statements, no-name-in-module
+"""A werewolf game implemented by agentscope."""
+from agentscope.agent import ReActAgent
+from agentscope.pipeline import MsgHub, fanout_pipeline, sequential_pipeline
+
+# Uncomment the following line to use Chinese prompts
+# from tutorial.example_werewolves.prompt import ChinesePrompts as Prompts
+from loguru import logger
+
+from tutorial.example_werewolves.prompt import EnglishPrompts as Prompts
+from tutorial.example_werewolves.structured_model import (
+ DiscussionModel,
+ WitchResurrectModel,
+ get_hunter_model,
+ get_poison_model,
+ get_seer_model,
+ get_vote_model,
+)
+from tutorial.example_werewolves.utils import (
+ MAX_DISCUSSION_ROUND,
+ MAX_GAME_ROUND,
+ EchoAgent,
+ Players,
+ majority_vote,
+ names_to_str,
+)
+
+
+class BadGuyException(Exception):
+ ...
+
+
+moderator = EchoAgent()
+# moderator.set_console_output_enabled(False)
+
+
+async def hunter_stage(
+ hunter_agent: ReActAgent,
+ players: Players,
+) -> str | None:
+ """Because the hunter's stage may happen in two places: killed at night
+ or voted during the day, we define a function here to avoid duplication."""
+ global moderator
+ msg_hunter = await hunter_agent(
+ await moderator(Prompts.to_hunter.format(name=hunter_agent.name)),
+ structured_model=get_hunter_model(players.current_alive),
+ )
+ if msg_hunter.metadata.get("shoot"):
+ return msg_hunter.metadata.get("name", None)
+ return None
+
+
+async def werewolves_game(agents: list[ReActAgent], roles) -> bool: # noqa: C901
+ """The main entry of the werewolf game
+
+ Args:
+ agents (`list[ReActAgent]`):
+ A list of 9 agents.
+ """
+ assert len(agents) == 9, "The werewolf game needs exactly 9 players."
+
+ # Init the players' status
+ players = Players()
+
+ # If the witch has healing and poison potion
+ healing, poison = True, True
+
+ # If it's the first day, the dead can leave a message
+ first_day = True
+
+ # Broadcast the game begin message
+ async with MsgHub(participants=agents) as greeting_hub:
+ await greeting_hub.broadcast(
+ await moderator(
+ Prompts.to_all_new_game.format(names_to_str(agents)),
+ ),
+ )
+
+ # Assign roles to the agents
+ for agent, role in zip(agents, roles):
+ # Tell the agent its role
+ await agent.observe(
+ await moderator(
+ f"[{agent.name} ONLY] {agent.name}, your role is {role}.",
+ ),
+ )
+ players.add_player(agent, role)
+
+ # Printing the roles
+ players.print_roles()
+
+ # GAME BEGIN!
+ for _ in range(MAX_GAME_ROUND):
+ # Create a MsgHub for all players to broadcast messages
+ async with MsgHub(
+ participants=players.current_alive,
+ enable_auto_broadcast=False, # manual broadcast only
+ name="alive_players",
+ ) as alive_players_hub:
+ # Night phase
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_night),
+ )
+ killed_player, poisoned_player, shot_player = None, None, None
+
+ try:
+ # Werewolves discuss
+ async with MsgHub(
+ players.werewolves,
+ enable_auto_broadcast=True,
+ announcement=await moderator(
+ Prompts.to_wolves_discussion.format(
+ names_to_str(players.werewolves),
+ names_to_str(players.current_alive),
+ ),
+ ),
+ name="werewolves",
+ ) as werewolves_hub:
+ # Discussion
+ n_werewolves = len(players.werewolves)
+ for _ in range(1, MAX_DISCUSSION_ROUND * n_werewolves + 1):
+ res = await players.werewolves[_ % n_werewolves](
+ structured_model=DiscussionModel,
+ )
+ if _ % n_werewolves == 0 and res.metadata.get(
+ "reach_agreement",
+ ):
+ break
+
+ # Werewolves vote
+ # Disable auto broadcast to avoid following other's votes
+ werewolves_hub.set_auto_broadcast(False)
+ msgs_vote = await fanout_pipeline(
+ players.werewolves,
+ msg=await moderator(content=Prompts.to_wolves_vote),
+ structured_model=get_vote_model(players.current_alive),
+ enable_gather=False,
+ )
+ killed_player, votes = majority_vote(
+ [_.metadata.get("vote") for _ in msgs_vote],
+ )
+ # Postpone the broadcast of voting
+ await werewolves_hub.broadcast(
+ [
+ *msgs_vote,
+ await moderator(
+ Prompts.to_wolves_res.format(votes, killed_player),
+ ),
+ ],
+ )
+ except Exception as e:
+ raise BadGuyException(
+ f"Werewolves failed to make a decision: {e}",
+ )
+
+ # Witch's turn
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_witch_turn),
+ )
+ msg_witch_poison = None
+ for agent in players.witch:
+ # Cannot heal witch herself
+ msg_witch_resurrect = None
+ if healing and killed_player != agent.name:
+ msg_witch_resurrect = await agent(
+ await moderator(
+ Prompts.to_witch_resurrect.format(
+ witch_name=agent.name,
+ dead_name=killed_player,
+ ),
+ ),
+ structured_model=WitchResurrectModel,
+ )
+ if msg_witch_resurrect.metadata.get("resurrect"):
+ killed_player = None
+ healing = False
+
+ # Has poison potion and hasn't used the healing potion
+ if poison and not (msg_witch_resurrect and msg_witch_resurrect.metadata["resurrect"]):
+ msg_witch_poison = await agent(
+ await moderator(
+ Prompts.to_witch_poison.format(
+ witch_name=agent.name,
+ ),
+ ),
+ structured_model=get_poison_model(
+ players.current_alive,
+ ),
+ )
+ if msg_witch_poison.metadata.get("poison"):
+ poisoned_player = msg_witch_poison.metadata.get("name")
+ poison = False
+
+ # Seer's turn
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_seer_turn),
+ )
+ for agent in players.seer:
+ msg_seer = await agent(
+ await moderator(
+ Prompts.to_seer.format(
+ agent.name,
+ names_to_str(players.current_alive),
+ ),
+ ),
+ structured_model=get_seer_model(players.current_alive),
+ )
+ if msg_seer.metadata.get("name"):
+ player = msg_seer.metadata["name"]
+ await agent.observe(
+ await moderator(
+ Prompts.to_seer_result.format(
+ agent_name=player,
+ role=players.name_to_role[player],
+ ),
+ ),
+ )
+
+ # Hunter's turn
+ for agent in players.hunter:
+ # If killed and not by witch's poison
+ if killed_player == agent.name and poisoned_player != agent.name:
+ shot_player = await hunter_stage(agent, players)
+
+ # Update alive players
+ dead_tonight = [killed_player, poisoned_player, shot_player]
+ players.update_players(dead_tonight)
+
+ # Day phase
+ if len([_ for _ in dead_tonight if _]) > 0:
+ await alive_players_hub.broadcast(
+ await moderator(
+ Prompts.to_all_day.format(
+ names_to_str([_ for _ in dead_tonight if _]),
+ ),
+ ),
+ )
+
+ # The killed player leave a last message in first night
+ if killed_player and first_day:
+ msg_moderator = await moderator(
+ Prompts.to_dead_player.format(killed_player),
+ )
+ await alive_players_hub.broadcast(msg_moderator)
+ # Leave a message
+ last_msg = await players.name_to_agent[killed_player]()
+ await alive_players_hub.broadcast(last_msg)
+
+ else:
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_peace),
+ )
+
+ # Check winning
+ res = players.check_winning()
+ if res:
+ await moderator(res)
+ break
+
+ # Discussion
+ await alive_players_hub.broadcast(
+ await moderator(
+ Prompts.to_all_discuss.format(
+ names=names_to_str(players.current_alive),
+ ),
+ ),
+ )
+ # Open the auto broadcast to enable discussion
+ alive_players_hub.set_auto_broadcast(True)
+ await sequential_pipeline(players.current_alive)
+ # Disable auto broadcast to avoid leaking info
+ alive_players_hub.set_auto_broadcast(False)
+
+ # Voting
+ msgs_vote = await fanout_pipeline(
+ players.current_alive,
+ await moderator(
+ Prompts.to_all_vote.format(
+ names_to_str(players.current_alive),
+ ),
+ ),
+ structured_model=get_vote_model(players.current_alive),
+ enable_gather=False,
+ )
+ voted_player, votes = majority_vote(
+ [_.metadata.get("vote") for _ in msgs_vote],
+ )
+ # Broadcast the voting messages together to avoid influencing
+ # each other
+ voting_msgs = [
+ *msgs_vote,
+ await moderator(
+ Prompts.to_all_res.format(votes, voted_player),
+ ),
+ ]
+
+ # Leave a message if voted
+ if voted_player:
+ prompt_msg = await moderator(
+ Prompts.to_dead_player.format(voted_player),
+ )
+ last_msg = await players.name_to_agent[voted_player](
+ prompt_msg,
+ )
+ voting_msgs.extend([prompt_msg, last_msg])
+
+ await alive_players_hub.broadcast(voting_msgs)
+
+ # If the voted player is the hunter, he can shoot someone
+ shot_player = None
+ for agent in players.hunter:
+ if voted_player == agent.name:
+ shot_player = await hunter_stage(agent, players)
+ if shot_player:
+ await alive_players_hub.broadcast(
+ await moderator(
+ Prompts.to_all_hunter_shoot.format(
+ shot_player,
+ ),
+ ),
+ )
+
+ # Update alive players
+ dead_today = [voted_player, shot_player]
+ players.update_players(dead_today)
+
+ # Check winning
+ res = players.check_winning()
+ if res:
+ async with MsgHub(players.all_players) as all_players_hub:
+ res_msg = await moderator(res)
+ await all_players_hub.broadcast(res_msg)
+ break
+
+ # The day ends
+ first_day = False
+
+ # # Game over, each player reflects
+ # await fanout_pipeline(
+ # agents=agents,
+ # msg=await moderator(Prompts.to_all_reflect),
+ # )
+
+ alive_wolves = players.werewolves
+ good_guy_win = len(alive_wolves) == 0
+ logger.warning("**********************************")
+ logger.warning(f"Good guy win: {good_guy_win}, alive werewolves: {alive_wolves}")
+ return good_guy_win
diff --git a/tutorial/example_werewolves/prompt.py b/tutorial/example_werewolves/prompt.py
new file mode 100644
index 00000000..d04306f0
--- /dev/null
+++ b/tutorial/example_werewolves/prompt.py
@@ -0,0 +1,106 @@
+# -*- coding: utf-8 -*-
+"""Default prompts"""
+
+
+class EnglishPrompts:
+ """English prompts used to guide the werewolf game."""
+
+ to_dead_player = "{}, you're eliminated now. Now you can make a final statement to " "all alive players before you leave the game."
+
+ to_all_new_game = "A new game is starting, the players are: {}. Now we randomly " "reassign the roles to each player and inform them of their roles " "privately."
+
+ to_all_night = "Night has fallen, everyone close your eyes. Werewolves open your " "eyes and choose a player to eliminate tonight."
+
+ to_wolves_discussion = "[WEREWOLVES ONLY] {}, you should discuss and " "decide on a player to eliminate tonight. Current alive players " "are {}. Remember to set `reach_agreement` to True if you reach an " "agreement during the discussion."
+
+ to_wolves_vote = "[WEREWOLVES ONLY] Which player do you vote to kill?"
+
+ to_wolves_res = "[WEREWOLVES ONLY] The voting result is {}. So you have chosen to " "eliminate {}."
+
+ to_all_witch_turn = "Witch's turn, witch open your eyes and decide your action tonight..."
+ to_witch_resurrect = "[WITCH ONLY] {witch_name}, you're the witch, and tonight {dead_name} " "is eliminated. You can resurrect him/her by using your healing " "potion, " "and note you can only use it once in the whole game. Do you want to " "resurrect {dead_name}? Give me your reason and decision."
+
+ to_witch_resurrect_no = "[WITCH ONLY] The witch has chosen not to resurrect the player."
+ to_witch_resurrect_yes = "[WITCH ONLY] The witch has chosen to resurrect the player."
+
+ to_witch_poison = "[WITCH ONLY] {witch_name}, as a witch, you have a one-time-use " "poison potion, do you want to use it tonight? Give me your reason " "and decision."
+
+ to_all_seer_turn = "Seer's turn, seer open your eyes and check one player's identity " "tonight..."
+
+ to_seer = "[SEER ONLY] {}, as the seer you can check one player's identity " "tonight. Who do you want to check? Give me your reason and decision."
+
+ to_seer_result = "[SEER ONLY] You've checked {agent_name}, and the result is: {role}."
+
+ to_hunter = "[HUNTER ONLY] {name}, as the hunter you're eliminated tonight. You " "can choose one player to take down with you. Also, you can choose " "not to use this ability. Give me your reason and decision."
+
+ to_all_hunter_shoot = "The hunter has chosen to shoot {} down with him/herself."
+
+ to_all_day = "The day is coming, all players open your eyes. Last night, " "the following player(s) has been eliminated: {}."
+
+ to_all_peace = "The day is coming, all the players open your eyes. Last night is " "peaceful, no player is eliminated."
+
+ to_all_discuss = "Now the alive players are {names}. The game goes on, it's time to " "discuss and vote a player to be eliminated. Now you each take turns " "to speak once in the order of {names}."
+
+ to_all_vote = "Now the discussion is over. Everyone, please vote to eliminate one " "player from the alive players: {}."
+
+ to_all_res = "The voting result is {}. So {} has been voted out."
+
+ to_all_wolf_win = "There are {n_alive} players alive, and {n_werewolves} of them are " "werewolves. " "The game is over and werewolves win🐺🎉!" "In this game, the true roles of all players are: {true_roles}"
+
+ to_all_village_win = "All the werewolves have been eliminated." "The game is over and villagers win🏘️🎉!" "In this game, the true roles of all players are: {true_roles}"
+
+ to_all_continue = "The game goes on."
+
+ to_all_reflect = "The game is over. Now each player can reflect on their performance. " "Note each player only has one chance to speak and the reflection is " "only visible to themselves."
+
+
+class ChinesePrompts:
+ """Chinese prompts used to guide the werewolf game."""
+
+ to_dead_player = "{}, 你已被淘汰。现在你可以向所有存活玩家发表最后的遗言。"
+
+ to_all_new_game = "新的一局游戏开始,参与玩家包括:{}。现在为每位玩家重新随机分配身份,并私下告知各自身份。"
+
+ to_all_night = "天黑了,请所有人闭眼。狼人请睁眼,选择今晚要淘汰的一名玩家..."
+
+ to_wolves_discussion = "[仅狼人可见] {}, 你们可以讨论并决定今晚要淘汰的玩家。当前存活玩家有:{}。" "如果达成一致,请将 `reach_agreement` 设为 True。"
+
+ to_wolves_vote = "[仅狼人可见] 你投票要杀死哪位玩家?"
+
+ to_wolves_res = "[仅狼人可见] 投票结果为 {},你们选择淘汰 {}。"
+
+ to_all_witch_turn = "轮到女巫行动,女巫请睁眼并决定今晚的操作..."
+ to_witch_resurrect = "[仅女巫可见] {witch_name},你是女巫,今晚{dead_name}被淘汰。" "你可以用解药救他/她,注意解药全局只能用一次。你要救{dead_name}吗?" "请给出理由和决定。"
+
+ to_witch_resurrect_no = "[仅女巫可见] 女巫选择不救该玩家。"
+ to_witch_resurrect_yes = "[仅女巫可见] 女巫选择救活该玩家。"
+
+ to_witch_poison = "[仅女巫可见] {witch_name},你有一瓶一次性毒药,今晚要使用吗?请给出理由和决定。"
+
+ to_all_seer_turn = "轮到预言家行动,预言家请睁眼并查验一名玩家身份..."
+
+ to_seer = "[仅预言家可见] {}, 你是预言家,今晚可以查验一名玩家身份。你要查谁?请给出理由和决定。"
+
+ to_seer_result = "[仅预言家可见] 你查验了{agent_name},结果是:{role}。"
+
+ to_hunter = "[仅猎人可见] {name},你是猎人,今晚被淘汰。你可以选择带走一名玩家,也可以选择不带走。请给出理由和决定。"
+
+ to_all_hunter_shoot = "猎人选择带走 {} 一起出局。"
+
+ to_all_day = "天亮了,请所有玩家睁眼。昨晚被淘汰的玩家有:{}。"
+
+ to_all_peace = "天亮了,请所有玩家睁眼。昨晚平安夜,无人被淘汰。"
+
+ to_all_discuss = "现在存活玩家有:{names}。游戏继续,大家开始讨论并投票淘汰一名玩家。请按顺序({names})依次发言。"
+
+ to_all_vote = "讨论结束。请大家从存活玩家中投票淘汰一人:{}。"
+
+ to_all_res = "投票结果为 {},{} 被淘汰。"
+
+ to_all_wolf_win = "当前存活玩家共{n_alive}人,其中{n_werewolves}人为狼人。" "游戏结束,狼人获胜🐺🎉!" "本局所有玩家真实身份为:{true_roles}"
+
+ to_all_village_win = "所有狼人已被淘汰。游戏结束,村民获胜🏘️🎉!本局所有玩家真实身份为:{true_roles}"
+
+ to_all_continue = "游戏继续。"
+
+ to_all_reflect = "游戏结束。现在每位玩家可以对自己的表现进行反思。注意每位玩家只有一次发言机会,且反思内容仅自己可见。"
diff --git a/tutorial/example_werewolves/start.py b/tutorial/example_werewolves/start.py
new file mode 100644
index 00000000..f9d27a53
--- /dev/null
+++ b/tutorial/example_werewolves/start.py
@@ -0,0 +1,147 @@
+# -*- coding: utf-8 -*-
+# flake8: noqa: E501
+
+"""The main entry point for the werewolf game."""
+
+from typing import List
+import numpy as np
+import dotenv
+
+dotenv.load_dotenv()
+
+from textwrap import dedent
+
+from agentscope.agent import ReActAgent
+from agentscope.formatter import DashScopeMultiAgentFormatter, OpenAIMultiAgentFormatter
+from agentscope.model import DashScopeChatModel, OpenAIChatModel
+from loguru import logger
+from pydantic import Field
+
+from ajet import AjetTuner, Workflow, WorkflowOutput, WorkflowTask
+from tutorial.example_werewolves.game import BadGuyException, werewolves_game
+
+
+def get_official_agent_prompt(name) -> str:
+ system_prompt = dedent(
+ f"""
+ You're a werewolf game player named {name}.
+
+ # YOUR TARGET
+ Your target is to win the game with your teammates as much as possible.
+
+ # GAME RULES
+ - In werewolf game, players are divided into three werewolves, three villagers, one seer, one hunter and one witch.
+ - Werewolves: kill one player each night, and must hide identity during the day.
+ - Villagers: ordinary players without special abilities, try to identify and eliminate werewolves.
+ - Seer: A special villager who can check one player's identity each night.
+ - Witch: A special villager with two one-time-use potions: a healing potion to save a player from being killed at night, and a poison to eliminate one player at night.
+ - Hunter: A special villager who can take one player down with them when they are eliminated.
+ - The game alternates between night and day phases until one side wins:
+ - Night Phase
+ - Werewolves choose one victim
+ - Seer checks one player's identity
+ - Witch decides whether to use potions
+ - Moderator announces who died during the night
+ - Day Phase
+ - All players discuss and vote to eliminate one suspected player
+
+ # GAME GUIDANCE
+ - Try your best to win the game with your teammates, tricks, lies, and deception are all allowed, e.g. pretending to be a different role.
+ - During discussion, don't be political, be direct and to the point.
+ - The day phase voting provides important clues. For example, the werewolves may vote together, attack the seer, etc.
+ ## GAME GUIDANCE FOR WEREWOLF
+ - Seer is your greatest threat, who can check one player's identity each night. Analyze players' speeches, find out the seer and eliminate him/her will greatly increase your chances of winning.
+ - In the first night, making random choices is common for werewolves since no information is available.
+ - Pretending to be other roles (seer, witch or villager) is a common strategy to hide your identity and mislead other villagers in the day phase.
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, if the dead player is hunter, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR SEER
+ - Seer is very important to villagers, exposing yourself too early may lead to being targeted by werewolves.
+ - Your ability to check one player's identity is crucial.
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, if the dead player is hunter, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR WITCH
+ - Witch has two powerful potions, use them wisely to protect key villagers or eliminate suspected werewolves.
+ - The outcome of the night phase provides important clues. For example, if the dead player is hunter, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR HUNTER
+ - Using your ability in day phase will expose your role (since only hunter can take one player down)
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR VILLAGER
+ - Protecting special villagers, especially the seer, is crucial for your team's success.
+ - Werewolves may pretend to be the seer. Be cautious and don't trust anyone easily.
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, if the dead player is hunter, etc. Use this information to adjust your strategy.
+
+ # NOTE
+ - [IMPORTANT] DO NOT make up any information that is not provided by the moderator or other players.
+ - This is a TEXT-based game, so DO NOT use or make up any non-textual information.
+ - Always critically reflect on whether your evidence exist, and avoid making assumptions.
+ - Your response should be specific and concise, provide clear reason and avoid unnecessary elaboration.
+ - Generate your one-line response by using the `generate_response` function.
+ - Don't repeat the others' speeches."""
+ )
+ return system_prompt
+
+
+class ExampleWerewolves(Workflow):
+ trainable_targets: List[str] | None = Field(default=["werewolf"], description="List of agents to be fine-tuned.")
+
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+ # ensure trainable targets is legal
+ assert self.trainable_targets is not None, "trainable_targets cannot be None in ExampleWerewolves (because we want to demonstrate a explicit multi-agent case)."
+
+ # bad guys and good guys cannot be trained simultaneously
+ # (because mix-cooperation-competition MARL needs too many advanced techniques to be displayed here)
+ if "werewolf" in self.trainable_targets:
+ assert len(self.trainable_targets) == 1, "Cannot train hostile roles simultaneously."
+ else:
+ assert len(self.trainable_targets) != 0, "No trainable targets specified."
+
+ # make and shuffle roles (fix random seed for reproducibility)
+ roles = ["werewolf"] * 3 + ["villager"] * 3 + ["seer", "witch", "hunter"]
+ task_id = workflow_task.task.metadata["random_number"]
+ np.random.seed(int(task_id))
+ np.random.shuffle(roles)
+
+ # initialize agents
+ players = []
+ for i, role in enumerate(roles):
+ default_model = OpenAIChatModel(
+ model_name="/mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen3-235B-A22B-Instruct-2507/",
+ stream=False,
+ client_args={"base_url": "http://22.17.52.4:2888/v1"},
+ api_key="no_api_key",
+ generate_kwargs={"temperature": 0.01},
+ )
+ model_for_this_agent = tuner.as_agentscope_model(
+ agent_name=f"Player{i + 1}", # the name of this agent
+ target_tag=role, # `target_tag in self.trainable_targets` means we train this agent, otherwise we do not train this agent.
+ debug_model=default_model, # the model used when this agent is not in `self.trainable_targets`
+ )
+ agent = ReActAgent(
+ name=f"Player{i + 1}",
+ sys_prompt=get_official_agent_prompt(f"Player{i + 1}"),
+ model=model_for_this_agent,
+ formatter=DashScopeMultiAgentFormatter() if role in self.trainable_targets else OpenAIMultiAgentFormatter(),
+ max_iters=3 if role in self.trainable_targets else 5,
+ )
+ # agent.set_console_output_enabled(False)
+ players += [agent]
+
+ # reward condition
+ try:
+ good_guy_win = await werewolves_game(players, roles)
+ raw_reward = 0
+ is_success = False
+ if (good_guy_win and self.trainable_targets[0] != "werewolf") or (not good_guy_win and self.trainable_targets[0] == "werewolf"):
+ raw_reward = 1
+ is_success = True
+ logger.warning(f"Raw reward: {raw_reward}")
+ logger.warning(f"Is success: {is_success}")
+ except BadGuyException as e:
+ logger.bind(exception=True).exception(f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent).")
+ raw_reward = -0.1
+ is_success = False
+ except Exception as e:
+ logger.bind(exception=True).exception(f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent).")
+ raw_reward = -0.1
+ is_success = False
+
+ return WorkflowOutput(reward=raw_reward, is_success=is_success)
diff --git a/tutorial/example_werewolves/structured_model.py b/tutorial/example_werewolves/structured_model.py
new file mode 100644
index 00000000..8e2ddb20
--- /dev/null
+++ b/tutorial/example_werewolves/structured_model.py
@@ -0,0 +1,86 @@
+# -*- coding: utf-8 -*-
+"""The structured output models used in the werewolf game."""
+from typing import Literal
+
+from agentscope.agent import AgentBase
+from pydantic import BaseModel, Field
+
+
+class DiscussionModel(BaseModel):
+ """The output format for discussion."""
+
+ reach_agreement: bool = Field(
+ description="Whether you have reached an agreement or not",
+ )
+
+
+def get_vote_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the vote model by player names."""
+
+ class VoteModel(BaseModel):
+ """The vote output format."""
+
+ vote: Literal[tuple(_.name for _ in agents)] = Field( # type: ignore
+ description="The name of the player you want to vote for",
+ )
+
+ return VoteModel
+
+
+class WitchResurrectModel(BaseModel):
+ """The output format for witch resurrect action."""
+
+ resurrect: bool = Field(
+ description="Whether you want to resurrect the player",
+ )
+
+
+def get_poison_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the poison model by player names."""
+
+ class WitchPoisonModel(BaseModel):
+ """The output format for witch poison action."""
+
+ poison: bool = Field(
+ description="Do you want to use the poison potion",
+ )
+ name: Literal[tuple(_.name for _ in agents)] | None = ( # type: ignore
+ Field(
+ description="The name of the player you want to poison, if you " "don't want to poison anyone, just leave it empty",
+ default=None,
+ )
+ )
+
+ return WitchPoisonModel
+
+
+def get_seer_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the seer model by player names."""
+
+ class SeerModel(BaseModel):
+ """The output format for seer action."""
+
+ name: Literal[tuple(_.name for _ in agents)] = Field( # type: ignore
+ description="The name of the player you want to check",
+ )
+
+ return SeerModel
+
+
+def get_hunter_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the hunter model by player agents."""
+
+ class HunterModel(BaseModel):
+ """The output format for hunter action."""
+
+ shoot: bool = Field(
+ description="Whether you want to use the shooting ability or not",
+ )
+ name: Literal[tuple(_.name for _ in agents)] | None = ( # type: ignore
+ Field(
+ description="The name of the player you want to shoot, if you " "don't want to the ability, just leave it empty",
+ default=None,
+ )
+ )
+
+ return HunterModel
diff --git a/tutorial/example_werewolves/utils.py b/tutorial/example_werewolves/utils.py
new file mode 100644
index 00000000..7261424e
--- /dev/null
+++ b/tutorial/example_werewolves/utils.py
@@ -0,0 +1,155 @@
+# -*- coding: utf-8 -*-
+"""Utility functions for the werewolf game."""
+from collections import defaultdict
+from typing import Any
+
+import numpy as np
+from agentscope.agent import AgentBase, ReActAgent
+from agentscope.message import Msg
+
+from tutorial.example_werewolves.prompt import EnglishPrompts as Prompts
+
+# MAX_GAME_ROUND = 30
+# MAX_DISCUSSION_ROUND = 3
+MAX_GAME_ROUND = 7
+MAX_DISCUSSION_ROUND = 2
+
+
+def majority_vote(votes: list[str]) -> tuple:
+ """Return the vote with the most counts."""
+ result = max(set(votes), key=votes.count)
+ names, counts = np.unique(votes, return_counts=True)
+ conditions = ", ".join(
+ [f"{name}: {count}" for name, count in zip(names, counts)],
+ )
+ return result, conditions
+
+
+def names_to_str(agents: list[str] | list[ReActAgent]) -> str:
+ """Return a string of agent names."""
+ if not agents:
+ return ""
+
+ if len(agents) == 1:
+ if isinstance(agents[0], ReActAgent):
+ return agents[0].name
+ return agents[0]
+
+ names = []
+ for agent in agents:
+ if isinstance(agent, ReActAgent):
+ names.append(agent.name)
+ else:
+ names.append(agent)
+ return ", ".join([*names[:-1], "and " + names[-1]])
+
+
+class EchoAgent(AgentBase):
+ """Echo agent that repeats the input message."""
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.name = "Moderator"
+
+ async def reply(self, content: str) -> Msg:
+ """Repeat the input content with its name and role."""
+ msg = Msg(
+ self.name,
+ content,
+ role="assistant",
+ )
+ await self.print(msg)
+ return msg
+
+ async def handle_interrupt(
+ self,
+ *args: Any,
+ **kwargs: Any,
+ ) -> Msg:
+ """Handle interrupt."""
+
+ async def observe(self, msg: Msg | list[Msg] | None) -> None:
+ """Observe the user's message."""
+
+
+class Players:
+ """Maintain the players' status."""
+
+ def __init__(self) -> None:
+ """Initialize the players."""
+ # The mapping from player name to role
+ self.name_to_role = {}
+ self.role_to_names = defaultdict(list)
+ self.name_to_agent = {}
+ self.werewolves = []
+ self.villagers = []
+ self.seer = []
+ self.hunter = []
+ self.witch = []
+ self.current_alive = []
+ self.all_players = []
+
+ def add_player(self, player: ReActAgent, role: str) -> None:
+ """Add a player to the game.
+
+ Args:
+ player (`ReActAgent`):
+ The player to be added.
+ role (`str`):
+ The role of the player.
+ """
+ self.name_to_role[player.name] = role
+ self.name_to_agent[player.name] = player
+ self.role_to_names[role].append(player.name)
+ self.all_players.append(player)
+ if role == "werewolf":
+ self.werewolves.append(player)
+ elif role == "villager":
+ self.villagers.append(player)
+ elif role == "seer":
+ self.seer.append(player)
+ elif role == "hunter":
+ self.hunter.append(player)
+ elif role == "witch":
+ self.witch.append(player)
+ else:
+ raise ValueError(f"Unknown role: {role}")
+ self.current_alive.append(player)
+
+ def update_players(self, dead_players: list[ReActAgent]) -> None:
+ """Update the current alive players.
+
+ Args:
+ dead_players (`list[ReActAgent]`):
+ A list of dead players to be removed.
+ """
+ self.werewolves = [_ for _ in self.werewolves if _.name not in dead_players]
+ self.villagers = [_ for _ in self.villagers if _.name not in dead_players]
+ self.seer = [_ for _ in self.seer if _.name not in dead_players]
+ self.hunter = [_ for _ in self.hunter if _.name not in dead_players]
+ self.witch = [_ for _ in self.witch if _.name not in dead_players]
+ self.current_alive = [_ for _ in self.current_alive if _.name not in dead_players]
+
+ def print_roles(self) -> None:
+ """Print the roles of all players."""
+ print("Roles:")
+ for name, role in self.name_to_role.items():
+ print(f" - {name}: {role}")
+
+ def check_winning(self) -> str | None:
+ """Check if the game is over and return the winning message."""
+
+ # Prepare true roles string
+ true_roles = f'{names_to_str(self.role_to_names["werewolf"])} are werewolves, ' f'{names_to_str(self.role_to_names["villager"])} are villagers, ' f'{names_to_str(self.role_to_names["seer"])} is the seer, ' f'{names_to_str(self.role_to_names["hunter"])} is the hunter, ' f'and {names_to_str(self.role_to_names["witch"])} is the witch.'
+
+ if len(self.werewolves) * 2 >= len(self.current_alive):
+ return Prompts.to_all_wolf_win.format(
+ n_alive=len(self.current_alive),
+ n_werewolves=len(self.werewolves),
+ true_roles=true_roles,
+ )
+ if self.current_alive and not self.werewolves:
+ return Prompts.to_all_village_win.format(
+ true_roles=true_roles,
+ )
+ return None
diff --git a/tutorial/example_werewolves/werewolves.md b/tutorial/example_werewolves/werewolves.md
new file mode 100644
index 00000000..e6528d2f
--- /dev/null
+++ b/tutorial/example_werewolves/werewolves.md
@@ -0,0 +1,4 @@
+# Training a basic math agent
+
+
+Please refer to document at [`docs/en/example_werewolves.md`](docs/en/example_werewolves.md)
diff --git a/tutorial/example_werewolves/werewolves.yaml b/tutorial/example_werewolves/werewolves.yaml
new file mode 100644
index 00000000..ac6d9e72
--- /dev/null
+++ b/tutorial/example_werewolves/werewolves.yaml
@@ -0,0 +1,76 @@
+# ------------------ main config ------------------
+ajet:
+ project_name: example_werewolves
+ task_reader:
+ type: random_dummy # ✨✨✨✨ `env_service` or `dataset_file` or `huggingface_dat_repo` or `random_dummy`
+
+ task_judge:
+ # ✨✨✨✨ select evaluation function
+ judge_protocol: null
+
+ model:
+ # ✨✨✨✨ select model to be trained
+ path: /mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2___5-7B-Instruct
+
+
+ rollout:
+ # the path to the workflow class
+ user_workflow: tutorial.example_werewolves.start->ExampleWerewolves # ✨✨✨✨ select agent
+
+ temperature: 0.7
+
+ max_env_worker: 64
+
+ num_repeat: 6
+
+ agent_madness_reward: 0.0
+
+ tensor_model_parallel_size: 1
+
+ # the number of vllm engines, number of gpus for infer is `n_vllm_engine*tensor_model_parallel_size`, this argument is NOT effective when NOT using trinity
+ n_vllm_engine: 8
+
+ max_num_seqs: 40
+
+ # monitor LLM's abormal behaviors during rollout
+ compute_madness_checklist:
+ - "nonsense"
+
+ max_response_length_in_one_turn: 1024
+
+ max_model_len: 22000
+
+ multi_turn:
+ # expected steps for each task run, used to calculate the training batch size for trinity, do not have to be precise
+ expected_steps: 3
+
+ debug:
+ debug_max_parallel: 1
+ debug_first_n_tasks: 1
+
+ data:
+ train_batch_size: 32
+ max_prompt_length: 4000
+ max_response_length: 18000
+
+ trainer_common:
+ save_freq: 5
+ test_freq: 99999
+ total_epochs: 99999
+ total_training_steps: 25
+ nnodes: 2
+ n_gpus_per_node: 8
+
+# ------------------ do not edit ------------------
+hydra:
+ searchpath:
+ - file://ajet/default_config
+ - file://ajet/default_config/verl # verl only
+ - file://ajet/default_config/trinity # trinity only
+
+# ------------------ do not edit ------------------
+defaults:
+ - verl_default # verl inherit 1/1
+ - trinity_default # trinity inherit 1/1
+ - ajet_default
+ - _self_
diff --git a/tutorial/figure/appworld.png b/tutorial/figure/appworld.png
new file mode 100644
index 00000000..c0ce5e86
Binary files /dev/null and b/tutorial/figure/appworld.png differ
diff --git a/tutorial/figure/werewolves_train_witch.png b/tutorial/figure/werewolves_train_witch.png
new file mode 100644
index 00000000..4232e95f
Binary files /dev/null and b/tutorial/figure/werewolves_train_witch.png differ
diff --git a/tutorial/math_agent.py b/tutorial/math_agent.py
deleted file mode 100644
index 084601b1..00000000
--- a/tutorial/math_agent.py
+++ /dev/null
@@ -1,69 +0,0 @@
-from astune.agentscope_flow import BeyondAgentProxy
-from agentscope.message import Msg
-from pydantic import BaseModel, Field
-from astune.protocol.agentscope_protocol import AgentScopeLearnProtocol
-from loguru import logger
-
-def extract_final_answer(result) -> str:
- """Extract the final answer from the agent's response."""
- try:
- if (
- hasattr(result, "metadata")
- and isinstance(result.metadata, dict)
- and "result" in result.metadata
- ):
- return result.metadata["result"]
- if hasattr(result, "content"):
- if isinstance(result.content, dict) and "result" in result.content:
- return result.content["result"]
- return str(result.content)
- return str(result)
- except Exception as e:
- logger.warning(f"Extract final answer error: {e}. Raw: {result}")
- return str(result)
-
-
-class FinalResult(BaseModel):
- result: str = Field(
- description="Your solution of the given math problem. Put your final answer in boxed format, e.g., \\boxed{42}"
- )
-
-system_prompt = """
-You are an agent specialized in solving math problems with tools. Please solve the math problem given to you. You can write and execute Python code to perform calculation or verify your answer. You should return your final answer within \\boxed{{}}.
-"""
-
-class ExampleMathLearn(AgentScopeLearnProtocol):
-
- trainer: str = Field(default="agentscorpion-trinity")
-
- async def agentscope_execute(self, init_messages, beyondagent_proxy: BeyondAgentProxy, config):
- from agentscope.agent import ReActAgent
- from agentscope.formatter import DashScopeChatFormatter
- from agentscope.memory import InMemoryMemory
- from agentscope.agent import ReActAgent
- from agentscope.memory import InMemoryMemory
- from agentscope.tool import Toolkit, execute_python_code
-
- if len(init_messages) >= 2: first_msg, init_messages = init_messages[0], init_messages[1:]
- else: first_msg = {"content": "You're a helpful assistant."}
- interaction_message = []
- for msg in init_messages:
- interaction_message.append(Msg(name=msg.get("name", "user"), content=msg.get("content", ""), role=msg.get("role", "user")))
-
- self.toolkit = Toolkit()
- self.toolkit.register_tool_function(execute_python_code)
- self.agent = ReActAgent(
- name="math_react_agent",
- sys_prompt=system_prompt,
- model=beyondagent_proxy, # type: ignore
- formatter=DashScopeChatFormatter(),
- toolkit=self.toolkit,
- memory=InMemoryMemory(),
- )
- msg = Msg("user", init_messages[0]['content'], role="user")
- result = await self.agent.reply(msg, structured_model=FinalResult)
- final_answer = extract_final_answer(result)
- beyondagent_proxy.update_judge_input_dictionary(final_answer=final_answer)
-
- return beyondagent_proxy
-
diff --git a/vsdb.py b/vsdb.py
deleted file mode 100644
index 28c11c37..00000000
--- a/vsdb.py
+++ /dev/null
@@ -1,114 +0,0 @@
-import os
-
-"""
-Ray Distributed Debugger VSCode Extension (Recommended)
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-1. Starting with Ray 2.39, Anyscale has introduced the `Ray Distributed Debugger
+
-- 找到日志文件夹,默认在 `./launcher_record/exp_yaml_file_name/*` 下面
+- 找到日志文件夹,默认在 `./saved_experiments/exp_yaml_file_name/*` 下面
- 运行 `beast_logger_go` 启动日志浏览器,vscode端口映射8181端口
```bash
root@xxxx:/xxx/xxx/xxx# beast_logger_go
@@ -160,12 +159,18 @@ INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8181 (Press CTRL+C to quit)
```
- 打开 http://127.0.0.1:8181,提示输入日志文件路径,填写日志文件夹的**绝对路径**,以下形式皆可
- - /mnt/data/qingxu.fu/astune/astune/launcher_record
- - /mnt/data/qingxu.fu/astune/astune/launcher_record/exp_yaml_file_name
- - /mnt/data/qingxu.fu/astune/astune/launcher_record/exp_yaml_file_name/2025_11_10_02_52/rollout
+ - /ajet/ajet/saved_experiments
+ - /ajet/ajet/saved_experiments/exp_yaml_file_name
+ - /ajet/ajet/saved_experiments/exp_yaml_file_name/2025_11_10_02_52/rollout
- 依次打开界面 **左侧** 的日志文件目标,**中间** 的日志条目,**右侧** 的交互记录,即可显示完整的轨迹
- 蓝色 Token 代表参与loss计算的 Token,黄色反之
-- 鼠标悬浮在 Token 上面可以查看 Token 的 **logprob** (暂时仅限trinity backbone)
\ No newline at end of file
+- 鼠标悬浮在 Token 上面可以查看 Token 的 **logprob** (暂时仅限trinity backbone)
+
+
+### 6. 参考训练曲线
+
+点击链接打开训练曲线:
+https://swanlab.cn/@binaryhusky/public/runs/96arcunrxlezdmcvmcdob/chart
diff --git a/tutorial/example_rubrics_judge/math_agent.py b/tutorial/example_rubrics_judge/math_agent.py
new file mode 100644
index 00000000..f035ac57
--- /dev/null
+++ b/tutorial/example_rubrics_judge/math_agent.py
@@ -0,0 +1,59 @@
+from agentscope.message import Msg
+from loguru import logger
+from pydantic import BaseModel, Field
+
+from ajet import AjetTuner, Workflow, WorkflowOutput, WorkflowTask
+
+
+def extract_final_answer(result) -> str:
+ """Extract the final answer from the agent's response."""
+ try:
+ if hasattr(result, "metadata") and isinstance(result.metadata, dict) and "result" in result.metadata:
+ return result.metadata["result"]
+ if hasattr(result, "content"):
+ if isinstance(result.content, dict) and "result" in result.content:
+ return result.content["result"]
+ return str(result.content)
+ return str(result)
+ except Exception as e:
+ logger.warning(f"Extract final answer error: {e}. Raw: {result}")
+ return str(result)
+
+
+class FinalResult(BaseModel):
+ result: str = Field(description="Your solution of the given math problem. Put your final answer in boxed format, e.g., \\boxed{42}")
+
+
+system_prompt = """
+You are an agent specialized in solving math problems with tools.
+Please solve the math problem given to you.
+You can write and execute Python code to perform calculation or verify your answer.
+You should return your final answer within \\boxed{{}}.
+"""
+
+
+class ExampleMathLearn(Workflow):
+ name: str = "math_agent_workflow"
+
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+ from agentscope.agent import ReActAgent
+ from agentscope.formatter import DashScopeChatFormatter
+ from agentscope.memory import InMemoryMemory
+ from agentscope.tool import Toolkit, execute_python_code
+
+ query = workflow_task.task.main_query
+ self.toolkit = Toolkit()
+ self.toolkit.register_tool_function(execute_python_code)
+ self.agent = ReActAgent(
+ name="math_react_agent",
+ sys_prompt=system_prompt,
+ model=tuner.as_agentscope_model(),
+ formatter=DashScopeChatFormatter(),
+ toolkit=self.toolkit,
+ memory=InMemoryMemory(),
+ )
+ self.agent.set_console_output_enabled(False)
+ msg = Msg("user", query, role="user")
+ result = await self.agent.reply(msg, structured_model=FinalResult)
+ final_answer = extract_final_answer(result)
+ return WorkflowOutput(reward=None, metadata={"final_answer": final_answer})
diff --git a/tutorial/example_rubrics_judge/r_judge.yaml b/tutorial/example_rubrics_judge/r_judge.yaml
new file mode 100644
index 00000000..f7a171ec
--- /dev/null
+++ b/tutorial/example_rubrics_judge/r_judge.yaml
@@ -0,0 +1,72 @@
+# ------------------ 主要配置 ------------------
+ajet:
+ project_name: example_rubrics_judge
+ task_reader:
+ type: huggingface_dat_repo # ✨✨✨✨ `env_service` or `dataset_file` or `huggingface_dat_repo`
+ # 如果选择 `huggingface_dat_repo` 以下配置生效
+ huggingface_dat_repo:
+ dataset_path: '/mnt/data_cpfs/qingxu.fu/dataset/openai/gsm8k/main'
+ training_split: "train"
+ validation_split: "test"
+
+ task_judge:
+ # ✨✨✨✨ 编写并选择评价函数
+ judge_type: rubrics_auto_grader # Options: 'customized_protocol', 'rubrics_auto_grader'
+ rubrics_auto_grader:
+ # rubrics begin
+ model_name: qwen-max
+ grader_mode: pointwise
+ language: en
+ min_score: 0
+ max_score: 1
+ success_threshold: 0.7
+ sampling_mode: all_samples
+ generate_number: 1
+ max_epochs: 2
+ max_retries: 3
+ aggregation_mode: keep_all
+ grader_name: Math Auto Grader
+ num_reference_samples: 20
+ query_field: main_query
+ answer_field: final_answer
+ reference_field: answer
+ input_data_type: dataset_file # `env_service` or `dataset_file` or `huggingface_dat_repo`
+ dataset_file:
+ training:
+ file_path: "tutorial/example_rm_auto_grader/rubrics_train.jsonl"
+
+
+ model:
+ # ✨✨✨✨ 设置待训练的模型
+ path: /mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2___5-14B-Instruct
+
+ rollout:
+ user_workflow: "tutorial.example_rubrics_judge.math_agent->ExampleMathLearn" # ✨✨✨✨ 编写并选择Agent
+ temperature: 0.7
+ max_env_worker: 80
+ num_repeat: 4
+ agent_madness_reward: 0.0
+
+ data:
+ train_batch_size: 64
+
+ debug:
+ debug_max_parallel: 1
+ debug_first_n_tasks: 1
+
+
+
+
+# ------------------ 不需要修改 ------------------
+hydra:
+ searchpath:
+ - file://ajet/default_config
+ - file://ajet/default_config/verl # verl only
+ - file://ajet/default_config/trinity # trinity only
+
+# ------------------ 不需要修改 ------------------
+defaults:
+ - verl_default # verl inherit 1/1
+ - trinity_default # trinity inherit 1/1
+ - ajet_default
+ - _self_
diff --git a/tutorial/example_werewolves/game.py b/tutorial/example_werewolves/game.py
new file mode 100644
index 00000000..7f72f9f9
--- /dev/null
+++ b/tutorial/example_werewolves/game.py
@@ -0,0 +1,349 @@
+# -*- coding: utf-8 -*-
+# pylint: disable=too-many-branches, too-many-statements, no-name-in-module
+"""A werewolf game implemented by agentscope."""
+from agentscope.agent import ReActAgent
+from agentscope.pipeline import MsgHub, fanout_pipeline, sequential_pipeline
+
+# Uncomment the following line to use Chinese prompts
+# from tutorial.example_werewolves.prompt import ChinesePrompts as Prompts
+from loguru import logger
+
+from tutorial.example_werewolves.prompt import EnglishPrompts as Prompts
+from tutorial.example_werewolves.structured_model import (
+ DiscussionModel,
+ WitchResurrectModel,
+ get_hunter_model,
+ get_poison_model,
+ get_seer_model,
+ get_vote_model,
+)
+from tutorial.example_werewolves.utils import (
+ MAX_DISCUSSION_ROUND,
+ MAX_GAME_ROUND,
+ EchoAgent,
+ Players,
+ majority_vote,
+ names_to_str,
+)
+
+
+class BadGuyException(Exception):
+ ...
+
+
+moderator = EchoAgent()
+# moderator.set_console_output_enabled(False)
+
+
+async def hunter_stage(
+ hunter_agent: ReActAgent,
+ players: Players,
+) -> str | None:
+ """Because the hunter's stage may happen in two places: killed at night
+ or voted during the day, we define a function here to avoid duplication."""
+ global moderator
+ msg_hunter = await hunter_agent(
+ await moderator(Prompts.to_hunter.format(name=hunter_agent.name)),
+ structured_model=get_hunter_model(players.current_alive),
+ )
+ if msg_hunter.metadata.get("shoot"):
+ return msg_hunter.metadata.get("name", None)
+ return None
+
+
+async def werewolves_game(agents: list[ReActAgent], roles) -> bool: # noqa: C901
+ """The main entry of the werewolf game
+
+ Args:
+ agents (`list[ReActAgent]`):
+ A list of 9 agents.
+ """
+ assert len(agents) == 9, "The werewolf game needs exactly 9 players."
+
+ # Init the players' status
+ players = Players()
+
+ # If the witch has healing and poison potion
+ healing, poison = True, True
+
+ # If it's the first day, the dead can leave a message
+ first_day = True
+
+ # Broadcast the game begin message
+ async with MsgHub(participants=agents) as greeting_hub:
+ await greeting_hub.broadcast(
+ await moderator(
+ Prompts.to_all_new_game.format(names_to_str(agents)),
+ ),
+ )
+
+ # Assign roles to the agents
+ for agent, role in zip(agents, roles):
+ # Tell the agent its role
+ await agent.observe(
+ await moderator(
+ f"[{agent.name} ONLY] {agent.name}, your role is {role}.",
+ ),
+ )
+ players.add_player(agent, role)
+
+ # Printing the roles
+ players.print_roles()
+
+ # GAME BEGIN!
+ for _ in range(MAX_GAME_ROUND):
+ # Create a MsgHub for all players to broadcast messages
+ async with MsgHub(
+ participants=players.current_alive,
+ enable_auto_broadcast=False, # manual broadcast only
+ name="alive_players",
+ ) as alive_players_hub:
+ # Night phase
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_night),
+ )
+ killed_player, poisoned_player, shot_player = None, None, None
+
+ try:
+ # Werewolves discuss
+ async with MsgHub(
+ players.werewolves,
+ enable_auto_broadcast=True,
+ announcement=await moderator(
+ Prompts.to_wolves_discussion.format(
+ names_to_str(players.werewolves),
+ names_to_str(players.current_alive),
+ ),
+ ),
+ name="werewolves",
+ ) as werewolves_hub:
+ # Discussion
+ n_werewolves = len(players.werewolves)
+ for _ in range(1, MAX_DISCUSSION_ROUND * n_werewolves + 1):
+ res = await players.werewolves[_ % n_werewolves](
+ structured_model=DiscussionModel,
+ )
+ if _ % n_werewolves == 0 and res.metadata.get(
+ "reach_agreement",
+ ):
+ break
+
+ # Werewolves vote
+ # Disable auto broadcast to avoid following other's votes
+ werewolves_hub.set_auto_broadcast(False)
+ msgs_vote = await fanout_pipeline(
+ players.werewolves,
+ msg=await moderator(content=Prompts.to_wolves_vote),
+ structured_model=get_vote_model(players.current_alive),
+ enable_gather=False,
+ )
+ killed_player, votes = majority_vote(
+ [_.metadata.get("vote") for _ in msgs_vote],
+ )
+ # Postpone the broadcast of voting
+ await werewolves_hub.broadcast(
+ [
+ *msgs_vote,
+ await moderator(
+ Prompts.to_wolves_res.format(votes, killed_player),
+ ),
+ ],
+ )
+ except Exception as e:
+ raise BadGuyException(
+ f"Werewolves failed to make a decision: {e}",
+ )
+
+ # Witch's turn
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_witch_turn),
+ )
+ msg_witch_poison = None
+ for agent in players.witch:
+ # Cannot heal witch herself
+ msg_witch_resurrect = None
+ if healing and killed_player != agent.name:
+ msg_witch_resurrect = await agent(
+ await moderator(
+ Prompts.to_witch_resurrect.format(
+ witch_name=agent.name,
+ dead_name=killed_player,
+ ),
+ ),
+ structured_model=WitchResurrectModel,
+ )
+ if msg_witch_resurrect.metadata.get("resurrect"):
+ killed_player = None
+ healing = False
+
+ # Has poison potion and hasn't used the healing potion
+ if poison and not (msg_witch_resurrect and msg_witch_resurrect.metadata["resurrect"]):
+ msg_witch_poison = await agent(
+ await moderator(
+ Prompts.to_witch_poison.format(
+ witch_name=agent.name,
+ ),
+ ),
+ structured_model=get_poison_model(
+ players.current_alive,
+ ),
+ )
+ if msg_witch_poison.metadata.get("poison"):
+ poisoned_player = msg_witch_poison.metadata.get("name")
+ poison = False
+
+ # Seer's turn
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_seer_turn),
+ )
+ for agent in players.seer:
+ msg_seer = await agent(
+ await moderator(
+ Prompts.to_seer.format(
+ agent.name,
+ names_to_str(players.current_alive),
+ ),
+ ),
+ structured_model=get_seer_model(players.current_alive),
+ )
+ if msg_seer.metadata.get("name"):
+ player = msg_seer.metadata["name"]
+ await agent.observe(
+ await moderator(
+ Prompts.to_seer_result.format(
+ agent_name=player,
+ role=players.name_to_role[player],
+ ),
+ ),
+ )
+
+ # Hunter's turn
+ for agent in players.hunter:
+ # If killed and not by witch's poison
+ if killed_player == agent.name and poisoned_player != agent.name:
+ shot_player = await hunter_stage(agent, players)
+
+ # Update alive players
+ dead_tonight = [killed_player, poisoned_player, shot_player]
+ players.update_players(dead_tonight)
+
+ # Day phase
+ if len([_ for _ in dead_tonight if _]) > 0:
+ await alive_players_hub.broadcast(
+ await moderator(
+ Prompts.to_all_day.format(
+ names_to_str([_ for _ in dead_tonight if _]),
+ ),
+ ),
+ )
+
+ # The killed player leave a last message in first night
+ if killed_player and first_day:
+ msg_moderator = await moderator(
+ Prompts.to_dead_player.format(killed_player),
+ )
+ await alive_players_hub.broadcast(msg_moderator)
+ # Leave a message
+ last_msg = await players.name_to_agent[killed_player]()
+ await alive_players_hub.broadcast(last_msg)
+
+ else:
+ await alive_players_hub.broadcast(
+ await moderator(Prompts.to_all_peace),
+ )
+
+ # Check winning
+ res = players.check_winning()
+ if res:
+ await moderator(res)
+ break
+
+ # Discussion
+ await alive_players_hub.broadcast(
+ await moderator(
+ Prompts.to_all_discuss.format(
+ names=names_to_str(players.current_alive),
+ ),
+ ),
+ )
+ # Open the auto broadcast to enable discussion
+ alive_players_hub.set_auto_broadcast(True)
+ await sequential_pipeline(players.current_alive)
+ # Disable auto broadcast to avoid leaking info
+ alive_players_hub.set_auto_broadcast(False)
+
+ # Voting
+ msgs_vote = await fanout_pipeline(
+ players.current_alive,
+ await moderator(
+ Prompts.to_all_vote.format(
+ names_to_str(players.current_alive),
+ ),
+ ),
+ structured_model=get_vote_model(players.current_alive),
+ enable_gather=False,
+ )
+ voted_player, votes = majority_vote(
+ [_.metadata.get("vote") for _ in msgs_vote],
+ )
+ # Broadcast the voting messages together to avoid influencing
+ # each other
+ voting_msgs = [
+ *msgs_vote,
+ await moderator(
+ Prompts.to_all_res.format(votes, voted_player),
+ ),
+ ]
+
+ # Leave a message if voted
+ if voted_player:
+ prompt_msg = await moderator(
+ Prompts.to_dead_player.format(voted_player),
+ )
+ last_msg = await players.name_to_agent[voted_player](
+ prompt_msg,
+ )
+ voting_msgs.extend([prompt_msg, last_msg])
+
+ await alive_players_hub.broadcast(voting_msgs)
+
+ # If the voted player is the hunter, he can shoot someone
+ shot_player = None
+ for agent in players.hunter:
+ if voted_player == agent.name:
+ shot_player = await hunter_stage(agent, players)
+ if shot_player:
+ await alive_players_hub.broadcast(
+ await moderator(
+ Prompts.to_all_hunter_shoot.format(
+ shot_player,
+ ),
+ ),
+ )
+
+ # Update alive players
+ dead_today = [voted_player, shot_player]
+ players.update_players(dead_today)
+
+ # Check winning
+ res = players.check_winning()
+ if res:
+ async with MsgHub(players.all_players) as all_players_hub:
+ res_msg = await moderator(res)
+ await all_players_hub.broadcast(res_msg)
+ break
+
+ # The day ends
+ first_day = False
+
+ # # Game over, each player reflects
+ # await fanout_pipeline(
+ # agents=agents,
+ # msg=await moderator(Prompts.to_all_reflect),
+ # )
+
+ alive_wolves = players.werewolves
+ good_guy_win = len(alive_wolves) == 0
+ logger.warning("**********************************")
+ logger.warning(f"Good guy win: {good_guy_win}, alive werewolves: {alive_wolves}")
+ return good_guy_win
diff --git a/tutorial/example_werewolves/prompt.py b/tutorial/example_werewolves/prompt.py
new file mode 100644
index 00000000..d04306f0
--- /dev/null
+++ b/tutorial/example_werewolves/prompt.py
@@ -0,0 +1,106 @@
+# -*- coding: utf-8 -*-
+"""Default prompts"""
+
+
+class EnglishPrompts:
+ """English prompts used to guide the werewolf game."""
+
+ to_dead_player = "{}, you're eliminated now. Now you can make a final statement to " "all alive players before you leave the game."
+
+ to_all_new_game = "A new game is starting, the players are: {}. Now we randomly " "reassign the roles to each player and inform them of their roles " "privately."
+
+ to_all_night = "Night has fallen, everyone close your eyes. Werewolves open your " "eyes and choose a player to eliminate tonight."
+
+ to_wolves_discussion = "[WEREWOLVES ONLY] {}, you should discuss and " "decide on a player to eliminate tonight. Current alive players " "are {}. Remember to set `reach_agreement` to True if you reach an " "agreement during the discussion."
+
+ to_wolves_vote = "[WEREWOLVES ONLY] Which player do you vote to kill?"
+
+ to_wolves_res = "[WEREWOLVES ONLY] The voting result is {}. So you have chosen to " "eliminate {}."
+
+ to_all_witch_turn = "Witch's turn, witch open your eyes and decide your action tonight..."
+ to_witch_resurrect = "[WITCH ONLY] {witch_name}, you're the witch, and tonight {dead_name} " "is eliminated. You can resurrect him/her by using your healing " "potion, " "and note you can only use it once in the whole game. Do you want to " "resurrect {dead_name}? Give me your reason and decision."
+
+ to_witch_resurrect_no = "[WITCH ONLY] The witch has chosen not to resurrect the player."
+ to_witch_resurrect_yes = "[WITCH ONLY] The witch has chosen to resurrect the player."
+
+ to_witch_poison = "[WITCH ONLY] {witch_name}, as a witch, you have a one-time-use " "poison potion, do you want to use it tonight? Give me your reason " "and decision."
+
+ to_all_seer_turn = "Seer's turn, seer open your eyes and check one player's identity " "tonight..."
+
+ to_seer = "[SEER ONLY] {}, as the seer you can check one player's identity " "tonight. Who do you want to check? Give me your reason and decision."
+
+ to_seer_result = "[SEER ONLY] You've checked {agent_name}, and the result is: {role}."
+
+ to_hunter = "[HUNTER ONLY] {name}, as the hunter you're eliminated tonight. You " "can choose one player to take down with you. Also, you can choose " "not to use this ability. Give me your reason and decision."
+
+ to_all_hunter_shoot = "The hunter has chosen to shoot {} down with him/herself."
+
+ to_all_day = "The day is coming, all players open your eyes. Last night, " "the following player(s) has been eliminated: {}."
+
+ to_all_peace = "The day is coming, all the players open your eyes. Last night is " "peaceful, no player is eliminated."
+
+ to_all_discuss = "Now the alive players are {names}. The game goes on, it's time to " "discuss and vote a player to be eliminated. Now you each take turns " "to speak once in the order of {names}."
+
+ to_all_vote = "Now the discussion is over. Everyone, please vote to eliminate one " "player from the alive players: {}."
+
+ to_all_res = "The voting result is {}. So {} has been voted out."
+
+ to_all_wolf_win = "There are {n_alive} players alive, and {n_werewolves} of them are " "werewolves. " "The game is over and werewolves win🐺🎉!" "In this game, the true roles of all players are: {true_roles}"
+
+ to_all_village_win = "All the werewolves have been eliminated." "The game is over and villagers win🏘️🎉!" "In this game, the true roles of all players are: {true_roles}"
+
+ to_all_continue = "The game goes on."
+
+ to_all_reflect = "The game is over. Now each player can reflect on their performance. " "Note each player only has one chance to speak and the reflection is " "only visible to themselves."
+
+
+class ChinesePrompts:
+ """Chinese prompts used to guide the werewolf game."""
+
+ to_dead_player = "{}, 你已被淘汰。现在你可以向所有存活玩家发表最后的遗言。"
+
+ to_all_new_game = "新的一局游戏开始,参与玩家包括:{}。现在为每位玩家重新随机分配身份,并私下告知各自身份。"
+
+ to_all_night = "天黑了,请所有人闭眼。狼人请睁眼,选择今晚要淘汰的一名玩家..."
+
+ to_wolves_discussion = "[仅狼人可见] {}, 你们可以讨论并决定今晚要淘汰的玩家。当前存活玩家有:{}。" "如果达成一致,请将 `reach_agreement` 设为 True。"
+
+ to_wolves_vote = "[仅狼人可见] 你投票要杀死哪位玩家?"
+
+ to_wolves_res = "[仅狼人可见] 投票结果为 {},你们选择淘汰 {}。"
+
+ to_all_witch_turn = "轮到女巫行动,女巫请睁眼并决定今晚的操作..."
+ to_witch_resurrect = "[仅女巫可见] {witch_name},你是女巫,今晚{dead_name}被淘汰。" "你可以用解药救他/她,注意解药全局只能用一次。你要救{dead_name}吗?" "请给出理由和决定。"
+
+ to_witch_resurrect_no = "[仅女巫可见] 女巫选择不救该玩家。"
+ to_witch_resurrect_yes = "[仅女巫可见] 女巫选择救活该玩家。"
+
+ to_witch_poison = "[仅女巫可见] {witch_name},你有一瓶一次性毒药,今晚要使用吗?请给出理由和决定。"
+
+ to_all_seer_turn = "轮到预言家行动,预言家请睁眼并查验一名玩家身份..."
+
+ to_seer = "[仅预言家可见] {}, 你是预言家,今晚可以查验一名玩家身份。你要查谁?请给出理由和决定。"
+
+ to_seer_result = "[仅预言家可见] 你查验了{agent_name},结果是:{role}。"
+
+ to_hunter = "[仅猎人可见] {name},你是猎人,今晚被淘汰。你可以选择带走一名玩家,也可以选择不带走。请给出理由和决定。"
+
+ to_all_hunter_shoot = "猎人选择带走 {} 一起出局。"
+
+ to_all_day = "天亮了,请所有玩家睁眼。昨晚被淘汰的玩家有:{}。"
+
+ to_all_peace = "天亮了,请所有玩家睁眼。昨晚平安夜,无人被淘汰。"
+
+ to_all_discuss = "现在存活玩家有:{names}。游戏继续,大家开始讨论并投票淘汰一名玩家。请按顺序({names})依次发言。"
+
+ to_all_vote = "讨论结束。请大家从存活玩家中投票淘汰一人:{}。"
+
+ to_all_res = "投票结果为 {},{} 被淘汰。"
+
+ to_all_wolf_win = "当前存活玩家共{n_alive}人,其中{n_werewolves}人为狼人。" "游戏结束,狼人获胜🐺🎉!" "本局所有玩家真实身份为:{true_roles}"
+
+ to_all_village_win = "所有狼人已被淘汰。游戏结束,村民获胜🏘️🎉!本局所有玩家真实身份为:{true_roles}"
+
+ to_all_continue = "游戏继续。"
+
+ to_all_reflect = "游戏结束。现在每位玩家可以对自己的表现进行反思。注意每位玩家只有一次发言机会,且反思内容仅自己可见。"
diff --git a/tutorial/example_werewolves/start.py b/tutorial/example_werewolves/start.py
new file mode 100644
index 00000000..f9d27a53
--- /dev/null
+++ b/tutorial/example_werewolves/start.py
@@ -0,0 +1,147 @@
+# -*- coding: utf-8 -*-
+# flake8: noqa: E501
+
+"""The main entry point for the werewolf game."""
+
+from typing import List
+import numpy as np
+import dotenv
+
+dotenv.load_dotenv()
+
+from textwrap import dedent
+
+from agentscope.agent import ReActAgent
+from agentscope.formatter import DashScopeMultiAgentFormatter, OpenAIMultiAgentFormatter
+from agentscope.model import DashScopeChatModel, OpenAIChatModel
+from loguru import logger
+from pydantic import Field
+
+from ajet import AjetTuner, Workflow, WorkflowOutput, WorkflowTask
+from tutorial.example_werewolves.game import BadGuyException, werewolves_game
+
+
+def get_official_agent_prompt(name) -> str:
+ system_prompt = dedent(
+ f"""
+ You're a werewolf game player named {name}.
+
+ # YOUR TARGET
+ Your target is to win the game with your teammates as much as possible.
+
+ # GAME RULES
+ - In werewolf game, players are divided into three werewolves, three villagers, one seer, one hunter and one witch.
+ - Werewolves: kill one player each night, and must hide identity during the day.
+ - Villagers: ordinary players without special abilities, try to identify and eliminate werewolves.
+ - Seer: A special villager who can check one player's identity each night.
+ - Witch: A special villager with two one-time-use potions: a healing potion to save a player from being killed at night, and a poison to eliminate one player at night.
+ - Hunter: A special villager who can take one player down with them when they are eliminated.
+ - The game alternates between night and day phases until one side wins:
+ - Night Phase
+ - Werewolves choose one victim
+ - Seer checks one player's identity
+ - Witch decides whether to use potions
+ - Moderator announces who died during the night
+ - Day Phase
+ - All players discuss and vote to eliminate one suspected player
+
+ # GAME GUIDANCE
+ - Try your best to win the game with your teammates, tricks, lies, and deception are all allowed, e.g. pretending to be a different role.
+ - During discussion, don't be political, be direct and to the point.
+ - The day phase voting provides important clues. For example, the werewolves may vote together, attack the seer, etc.
+ ## GAME GUIDANCE FOR WEREWOLF
+ - Seer is your greatest threat, who can check one player's identity each night. Analyze players' speeches, find out the seer and eliminate him/her will greatly increase your chances of winning.
+ - In the first night, making random choices is common for werewolves since no information is available.
+ - Pretending to be other roles (seer, witch or villager) is a common strategy to hide your identity and mislead other villagers in the day phase.
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, if the dead player is hunter, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR SEER
+ - Seer is very important to villagers, exposing yourself too early may lead to being targeted by werewolves.
+ - Your ability to check one player's identity is crucial.
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, if the dead player is hunter, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR WITCH
+ - Witch has two powerful potions, use them wisely to protect key villagers or eliminate suspected werewolves.
+ - The outcome of the night phase provides important clues. For example, if the dead player is hunter, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR HUNTER
+ - Using your ability in day phase will expose your role (since only hunter can take one player down)
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, etc. Use this information to adjust your strategy.
+ ## GAME GUIDANCE FOR VILLAGER
+ - Protecting special villagers, especially the seer, is crucial for your team's success.
+ - Werewolves may pretend to be the seer. Be cautious and don't trust anyone easily.
+ - The outcome of the night phase provides important clues. For example, if witch uses the healing or poison potion, if the dead player is hunter, etc. Use this information to adjust your strategy.
+
+ # NOTE
+ - [IMPORTANT] DO NOT make up any information that is not provided by the moderator or other players.
+ - This is a TEXT-based game, so DO NOT use or make up any non-textual information.
+ - Always critically reflect on whether your evidence exist, and avoid making assumptions.
+ - Your response should be specific and concise, provide clear reason and avoid unnecessary elaboration.
+ - Generate your one-line response by using the `generate_response` function.
+ - Don't repeat the others' speeches."""
+ )
+ return system_prompt
+
+
+class ExampleWerewolves(Workflow):
+ trainable_targets: List[str] | None = Field(default=["werewolf"], description="List of agents to be fine-tuned.")
+
+ async def execute(self, workflow_task: WorkflowTask, tuner: AjetTuner) -> WorkflowOutput:
+ # ensure trainable targets is legal
+ assert self.trainable_targets is not None, "trainable_targets cannot be None in ExampleWerewolves (because we want to demonstrate a explicit multi-agent case)."
+
+ # bad guys and good guys cannot be trained simultaneously
+ # (because mix-cooperation-competition MARL needs too many advanced techniques to be displayed here)
+ if "werewolf" in self.trainable_targets:
+ assert len(self.trainable_targets) == 1, "Cannot train hostile roles simultaneously."
+ else:
+ assert len(self.trainable_targets) != 0, "No trainable targets specified."
+
+ # make and shuffle roles (fix random seed for reproducibility)
+ roles = ["werewolf"] * 3 + ["villager"] * 3 + ["seer", "witch", "hunter"]
+ task_id = workflow_task.task.metadata["random_number"]
+ np.random.seed(int(task_id))
+ np.random.shuffle(roles)
+
+ # initialize agents
+ players = []
+ for i, role in enumerate(roles):
+ default_model = OpenAIChatModel(
+ model_name="/mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen3-235B-A22B-Instruct-2507/",
+ stream=False,
+ client_args={"base_url": "http://22.17.52.4:2888/v1"},
+ api_key="no_api_key",
+ generate_kwargs={"temperature": 0.01},
+ )
+ model_for_this_agent = tuner.as_agentscope_model(
+ agent_name=f"Player{i + 1}", # the name of this agent
+ target_tag=role, # `target_tag in self.trainable_targets` means we train this agent, otherwise we do not train this agent.
+ debug_model=default_model, # the model used when this agent is not in `self.trainable_targets`
+ )
+ agent = ReActAgent(
+ name=f"Player{i + 1}",
+ sys_prompt=get_official_agent_prompt(f"Player{i + 1}"),
+ model=model_for_this_agent,
+ formatter=DashScopeMultiAgentFormatter() if role in self.trainable_targets else OpenAIMultiAgentFormatter(),
+ max_iters=3 if role in self.trainable_targets else 5,
+ )
+ # agent.set_console_output_enabled(False)
+ players += [agent]
+
+ # reward condition
+ try:
+ good_guy_win = await werewolves_game(players, roles)
+ raw_reward = 0
+ is_success = False
+ if (good_guy_win and self.trainable_targets[0] != "werewolf") or (not good_guy_win and self.trainable_targets[0] == "werewolf"):
+ raw_reward = 1
+ is_success = True
+ logger.warning(f"Raw reward: {raw_reward}")
+ logger.warning(f"Is success: {is_success}")
+ except BadGuyException as e:
+ logger.bind(exception=True).exception(f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent).")
+ raw_reward = -0.1
+ is_success = False
+ except Exception as e:
+ logger.bind(exception=True).exception(f"Error during game execution. Game cannot continue, whatever the cause, let's punish trainable agents (Although they maybe innocent).")
+ raw_reward = -0.1
+ is_success = False
+
+ return WorkflowOutput(reward=raw_reward, is_success=is_success)
diff --git a/tutorial/example_werewolves/structured_model.py b/tutorial/example_werewolves/structured_model.py
new file mode 100644
index 00000000..8e2ddb20
--- /dev/null
+++ b/tutorial/example_werewolves/structured_model.py
@@ -0,0 +1,86 @@
+# -*- coding: utf-8 -*-
+"""The structured output models used in the werewolf game."""
+from typing import Literal
+
+from agentscope.agent import AgentBase
+from pydantic import BaseModel, Field
+
+
+class DiscussionModel(BaseModel):
+ """The output format for discussion."""
+
+ reach_agreement: bool = Field(
+ description="Whether you have reached an agreement or not",
+ )
+
+
+def get_vote_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the vote model by player names."""
+
+ class VoteModel(BaseModel):
+ """The vote output format."""
+
+ vote: Literal[tuple(_.name for _ in agents)] = Field( # type: ignore
+ description="The name of the player you want to vote for",
+ )
+
+ return VoteModel
+
+
+class WitchResurrectModel(BaseModel):
+ """The output format for witch resurrect action."""
+
+ resurrect: bool = Field(
+ description="Whether you want to resurrect the player",
+ )
+
+
+def get_poison_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the poison model by player names."""
+
+ class WitchPoisonModel(BaseModel):
+ """The output format for witch poison action."""
+
+ poison: bool = Field(
+ description="Do you want to use the poison potion",
+ )
+ name: Literal[tuple(_.name for _ in agents)] | None = ( # type: ignore
+ Field(
+ description="The name of the player you want to poison, if you " "don't want to poison anyone, just leave it empty",
+ default=None,
+ )
+ )
+
+ return WitchPoisonModel
+
+
+def get_seer_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the seer model by player names."""
+
+ class SeerModel(BaseModel):
+ """The output format for seer action."""
+
+ name: Literal[tuple(_.name for _ in agents)] = Field( # type: ignore
+ description="The name of the player you want to check",
+ )
+
+ return SeerModel
+
+
+def get_hunter_model(agents: list[AgentBase]) -> type[BaseModel]:
+ """Get the hunter model by player agents."""
+
+ class HunterModel(BaseModel):
+ """The output format for hunter action."""
+
+ shoot: bool = Field(
+ description="Whether you want to use the shooting ability or not",
+ )
+ name: Literal[tuple(_.name for _ in agents)] | None = ( # type: ignore
+ Field(
+ description="The name of the player you want to shoot, if you " "don't want to the ability, just leave it empty",
+ default=None,
+ )
+ )
+
+ return HunterModel
diff --git a/tutorial/example_werewolves/utils.py b/tutorial/example_werewolves/utils.py
new file mode 100644
index 00000000..7261424e
--- /dev/null
+++ b/tutorial/example_werewolves/utils.py
@@ -0,0 +1,155 @@
+# -*- coding: utf-8 -*-
+"""Utility functions for the werewolf game."""
+from collections import defaultdict
+from typing import Any
+
+import numpy as np
+from agentscope.agent import AgentBase, ReActAgent
+from agentscope.message import Msg
+
+from tutorial.example_werewolves.prompt import EnglishPrompts as Prompts
+
+# MAX_GAME_ROUND = 30
+# MAX_DISCUSSION_ROUND = 3
+MAX_GAME_ROUND = 7
+MAX_DISCUSSION_ROUND = 2
+
+
+def majority_vote(votes: list[str]) -> tuple:
+ """Return the vote with the most counts."""
+ result = max(set(votes), key=votes.count)
+ names, counts = np.unique(votes, return_counts=True)
+ conditions = ", ".join(
+ [f"{name}: {count}" for name, count in zip(names, counts)],
+ )
+ return result, conditions
+
+
+def names_to_str(agents: list[str] | list[ReActAgent]) -> str:
+ """Return a string of agent names."""
+ if not agents:
+ return ""
+
+ if len(agents) == 1:
+ if isinstance(agents[0], ReActAgent):
+ return agents[0].name
+ return agents[0]
+
+ names = []
+ for agent in agents:
+ if isinstance(agent, ReActAgent):
+ names.append(agent.name)
+ else:
+ names.append(agent)
+ return ", ".join([*names[:-1], "and " + names[-1]])
+
+
+class EchoAgent(AgentBase):
+ """Echo agent that repeats the input message."""
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.name = "Moderator"
+
+ async def reply(self, content: str) -> Msg:
+ """Repeat the input content with its name and role."""
+ msg = Msg(
+ self.name,
+ content,
+ role="assistant",
+ )
+ await self.print(msg)
+ return msg
+
+ async def handle_interrupt(
+ self,
+ *args: Any,
+ **kwargs: Any,
+ ) -> Msg:
+ """Handle interrupt."""
+
+ async def observe(self, msg: Msg | list[Msg] | None) -> None:
+ """Observe the user's message."""
+
+
+class Players:
+ """Maintain the players' status."""
+
+ def __init__(self) -> None:
+ """Initialize the players."""
+ # The mapping from player name to role
+ self.name_to_role = {}
+ self.role_to_names = defaultdict(list)
+ self.name_to_agent = {}
+ self.werewolves = []
+ self.villagers = []
+ self.seer = []
+ self.hunter = []
+ self.witch = []
+ self.current_alive = []
+ self.all_players = []
+
+ def add_player(self, player: ReActAgent, role: str) -> None:
+ """Add a player to the game.
+
+ Args:
+ player (`ReActAgent`):
+ The player to be added.
+ role (`str`):
+ The role of the player.
+ """
+ self.name_to_role[player.name] = role
+ self.name_to_agent[player.name] = player
+ self.role_to_names[role].append(player.name)
+ self.all_players.append(player)
+ if role == "werewolf":
+ self.werewolves.append(player)
+ elif role == "villager":
+ self.villagers.append(player)
+ elif role == "seer":
+ self.seer.append(player)
+ elif role == "hunter":
+ self.hunter.append(player)
+ elif role == "witch":
+ self.witch.append(player)
+ else:
+ raise ValueError(f"Unknown role: {role}")
+ self.current_alive.append(player)
+
+ def update_players(self, dead_players: list[ReActAgent]) -> None:
+ """Update the current alive players.
+
+ Args:
+ dead_players (`list[ReActAgent]`):
+ A list of dead players to be removed.
+ """
+ self.werewolves = [_ for _ in self.werewolves if _.name not in dead_players]
+ self.villagers = [_ for _ in self.villagers if _.name not in dead_players]
+ self.seer = [_ for _ in self.seer if _.name not in dead_players]
+ self.hunter = [_ for _ in self.hunter if _.name not in dead_players]
+ self.witch = [_ for _ in self.witch if _.name not in dead_players]
+ self.current_alive = [_ for _ in self.current_alive if _.name not in dead_players]
+
+ def print_roles(self) -> None:
+ """Print the roles of all players."""
+ print("Roles:")
+ for name, role in self.name_to_role.items():
+ print(f" - {name}: {role}")
+
+ def check_winning(self) -> str | None:
+ """Check if the game is over and return the winning message."""
+
+ # Prepare true roles string
+ true_roles = f'{names_to_str(self.role_to_names["werewolf"])} are werewolves, ' f'{names_to_str(self.role_to_names["villager"])} are villagers, ' f'{names_to_str(self.role_to_names["seer"])} is the seer, ' f'{names_to_str(self.role_to_names["hunter"])} is the hunter, ' f'and {names_to_str(self.role_to_names["witch"])} is the witch.'
+
+ if len(self.werewolves) * 2 >= len(self.current_alive):
+ return Prompts.to_all_wolf_win.format(
+ n_alive=len(self.current_alive),
+ n_werewolves=len(self.werewolves),
+ true_roles=true_roles,
+ )
+ if self.current_alive and not self.werewolves:
+ return Prompts.to_all_village_win.format(
+ true_roles=true_roles,
+ )
+ return None
diff --git a/tutorial/example_werewolves/werewolves.md b/tutorial/example_werewolves/werewolves.md
new file mode 100644
index 00000000..e6528d2f
--- /dev/null
+++ b/tutorial/example_werewolves/werewolves.md
@@ -0,0 +1,4 @@
+# Training a basic math agent
+
+
+Please refer to document at [`docs/en/example_werewolves.md`](docs/en/example_werewolves.md)
diff --git a/tutorial/example_werewolves/werewolves.yaml b/tutorial/example_werewolves/werewolves.yaml
new file mode 100644
index 00000000..ac6d9e72
--- /dev/null
+++ b/tutorial/example_werewolves/werewolves.yaml
@@ -0,0 +1,76 @@
+# ------------------ main config ------------------
+ajet:
+ project_name: example_werewolves
+ task_reader:
+ type: random_dummy # ✨✨✨✨ `env_service` or `dataset_file` or `huggingface_dat_repo` or `random_dummy`
+
+ task_judge:
+ # ✨✨✨✨ select evaluation function
+ judge_protocol: null
+
+ model:
+ # ✨✨✨✨ select model to be trained
+ path: /mnt/data_cpfs/model_cache/modelscope/hub/Qwen/Qwen/Qwen2___5-7B-Instruct
+
+
+ rollout:
+ # the path to the workflow class
+ user_workflow: tutorial.example_werewolves.start->ExampleWerewolves # ✨✨✨✨ select agent
+
+ temperature: 0.7
+
+ max_env_worker: 64
+
+ num_repeat: 6
+
+ agent_madness_reward: 0.0
+
+ tensor_model_parallel_size: 1
+
+ # the number of vllm engines, number of gpus for infer is `n_vllm_engine*tensor_model_parallel_size`, this argument is NOT effective when NOT using trinity
+ n_vllm_engine: 8
+
+ max_num_seqs: 40
+
+ # monitor LLM's abormal behaviors during rollout
+ compute_madness_checklist:
+ - "nonsense"
+
+ max_response_length_in_one_turn: 1024
+
+ max_model_len: 22000
+
+ multi_turn:
+ # expected steps for each task run, used to calculate the training batch size for trinity, do not have to be precise
+ expected_steps: 3
+
+ debug:
+ debug_max_parallel: 1
+ debug_first_n_tasks: 1
+
+ data:
+ train_batch_size: 32
+ max_prompt_length: 4000
+ max_response_length: 18000
+
+ trainer_common:
+ save_freq: 5
+ test_freq: 99999
+ total_epochs: 99999
+ total_training_steps: 25
+ nnodes: 2
+ n_gpus_per_node: 8
+
+# ------------------ do not edit ------------------
+hydra:
+ searchpath:
+ - file://ajet/default_config
+ - file://ajet/default_config/verl # verl only
+ - file://ajet/default_config/trinity # trinity only
+
+# ------------------ do not edit ------------------
+defaults:
+ - verl_default # verl inherit 1/1
+ - trinity_default # trinity inherit 1/1
+ - ajet_default
+ - _self_
diff --git a/tutorial/figure/appworld.png b/tutorial/figure/appworld.png
new file mode 100644
index 00000000..c0ce5e86
Binary files /dev/null and b/tutorial/figure/appworld.png differ
diff --git a/tutorial/figure/werewolves_train_witch.png b/tutorial/figure/werewolves_train_witch.png
new file mode 100644
index 00000000..4232e95f
Binary files /dev/null and b/tutorial/figure/werewolves_train_witch.png differ
diff --git a/tutorial/math_agent.py b/tutorial/math_agent.py
deleted file mode 100644
index 084601b1..00000000
--- a/tutorial/math_agent.py
+++ /dev/null
@@ -1,69 +0,0 @@
-from astune.agentscope_flow import BeyondAgentProxy
-from agentscope.message import Msg
-from pydantic import BaseModel, Field
-from astune.protocol.agentscope_protocol import AgentScopeLearnProtocol
-from loguru import logger
-
-def extract_final_answer(result) -> str:
- """Extract the final answer from the agent's response."""
- try:
- if (
- hasattr(result, "metadata")
- and isinstance(result.metadata, dict)
- and "result" in result.metadata
- ):
- return result.metadata["result"]
- if hasattr(result, "content"):
- if isinstance(result.content, dict) and "result" in result.content:
- return result.content["result"]
- return str(result.content)
- return str(result)
- except Exception as e:
- logger.warning(f"Extract final answer error: {e}. Raw: {result}")
- return str(result)
-
-
-class FinalResult(BaseModel):
- result: str = Field(
- description="Your solution of the given math problem. Put your final answer in boxed format, e.g., \\boxed{42}"
- )
-
-system_prompt = """
-You are an agent specialized in solving math problems with tools. Please solve the math problem given to you. You can write and execute Python code to perform calculation or verify your answer. You should return your final answer within \\boxed{{}}.
-"""
-
-class ExampleMathLearn(AgentScopeLearnProtocol):
-
- trainer: str = Field(default="agentscorpion-trinity")
-
- async def agentscope_execute(self, init_messages, beyondagent_proxy: BeyondAgentProxy, config):
- from agentscope.agent import ReActAgent
- from agentscope.formatter import DashScopeChatFormatter
- from agentscope.memory import InMemoryMemory
- from agentscope.agent import ReActAgent
- from agentscope.memory import InMemoryMemory
- from agentscope.tool import Toolkit, execute_python_code
-
- if len(init_messages) >= 2: first_msg, init_messages = init_messages[0], init_messages[1:]
- else: first_msg = {"content": "You're a helpful assistant."}
- interaction_message = []
- for msg in init_messages:
- interaction_message.append(Msg(name=msg.get("name", "user"), content=msg.get("content", ""), role=msg.get("role", "user")))
-
- self.toolkit = Toolkit()
- self.toolkit.register_tool_function(execute_python_code)
- self.agent = ReActAgent(
- name="math_react_agent",
- sys_prompt=system_prompt,
- model=beyondagent_proxy, # type: ignore
- formatter=DashScopeChatFormatter(),
- toolkit=self.toolkit,
- memory=InMemoryMemory(),
- )
- msg = Msg("user", init_messages[0]['content'], role="user")
- result = await self.agent.reply(msg, structured_model=FinalResult)
- final_answer = extract_final_answer(result)
- beyondagent_proxy.update_judge_input_dictionary(final_answer=final_answer)
-
- return beyondagent_proxy
-
diff --git a/vsdb.py b/vsdb.py
deleted file mode 100644
index 28c11c37..00000000
--- a/vsdb.py
+++ /dev/null
@@ -1,114 +0,0 @@
-import os
-
-"""
-Ray Distributed Debugger VSCode Extension (Recommended)
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-1. Starting with Ray 2.39, Anyscale has introduced the `Ray Distributed Debugger